
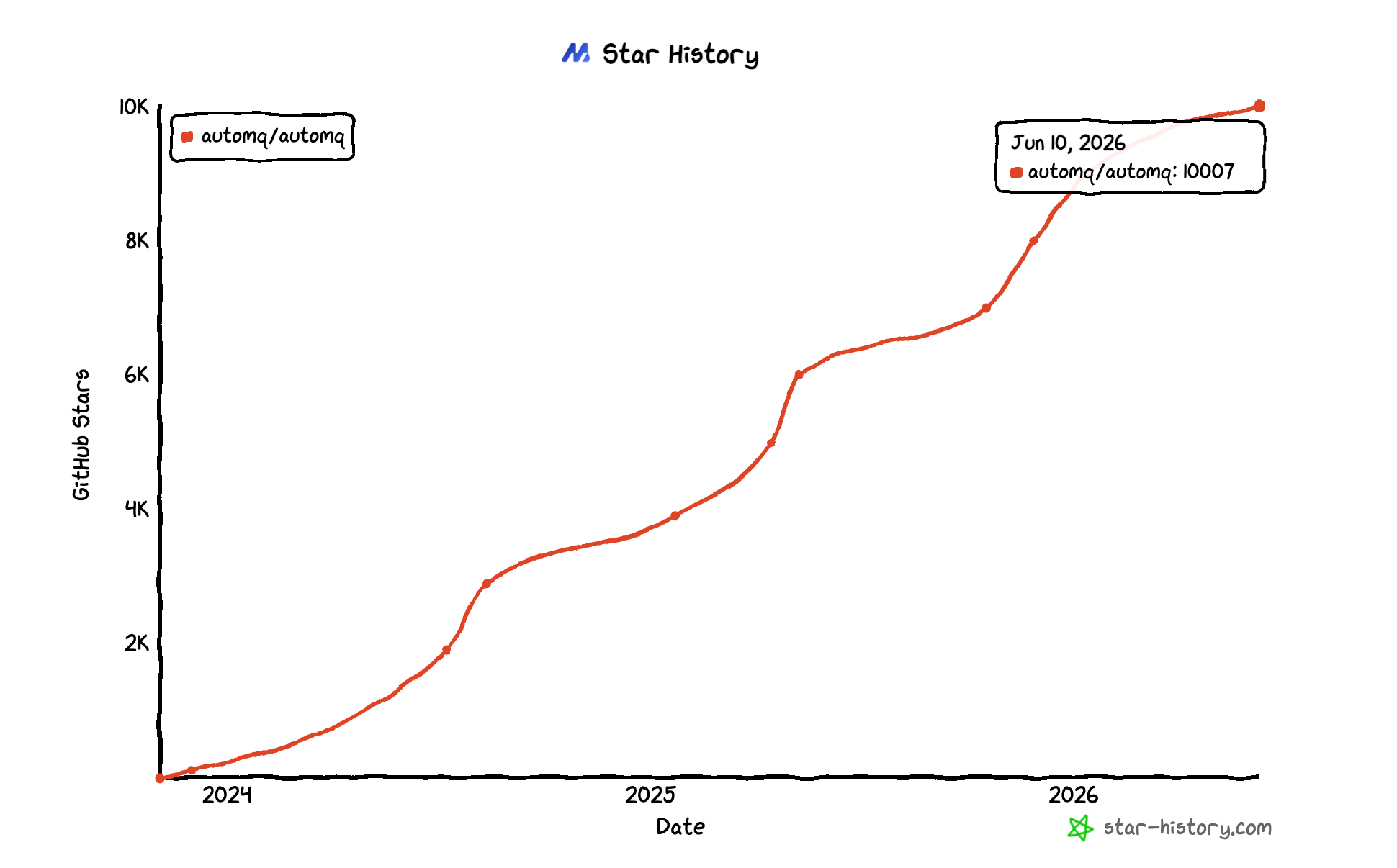
2026 年 6 月,AutoMQ 开源仓库突破 10K GitHub Star。写下这句话的时候,我们很开心,也很感谢一路关注、试用、提 issue、给反馈的开发者和用户。
基础软件的 Star 通常来得慢一些。开发者点下 Star 之前,往往已经读过架构、跑过 demo、翻过 issue;企业团队愿意把它放进 Kafka 选型,也会先评估兼容性、可靠性、迁移成本和长期运维。AutoMQ 的 10K Star 里,有这样的耐心和真实反馈。根据 OSSInsight 的 GitHub 关注来源统计,约 74% 的关注来自海外;同时,AutoMQ 已经进入中国、东南亚、欧洲和美国企业的生产环境。这个结果让我们很受鼓舞。
AutoMQ 开源时,我们想推动的是 Kafka 在云时代的存储架构演进。Kafka 已经沉淀了成熟的协议、语义和生态,这些能力应该继续保留;持久数据长期绑在 Broker 本地磁盘上,会把数据中心时代的弹性、成本和运维压力带到云上。AutoMQ 选择 Diskless Kafka,把流数据存储放到对象存储和共享存储之上,让 Broker 成为无状态计算节点,同时保留 Kafka 成熟的协议、语义和生态。AutoMQ 也是围绕这条路线最早开源并持续投入生产实践的 Diskless Kafka 项目之一。
从 10K Star 往回看,AutoMQ 的增长曲线背后有开发者的工程追问、社区里的架构讨论、客户生产环境里的验证,也有一支中国开源基础软件团队走向全球市场的过程。沿着这些经历往下看,就能看到越来越多 Kafka 工程师和平台团队开始关注 Diskless Kafka 的原因。
Diskless Kafka 开拓者亮相
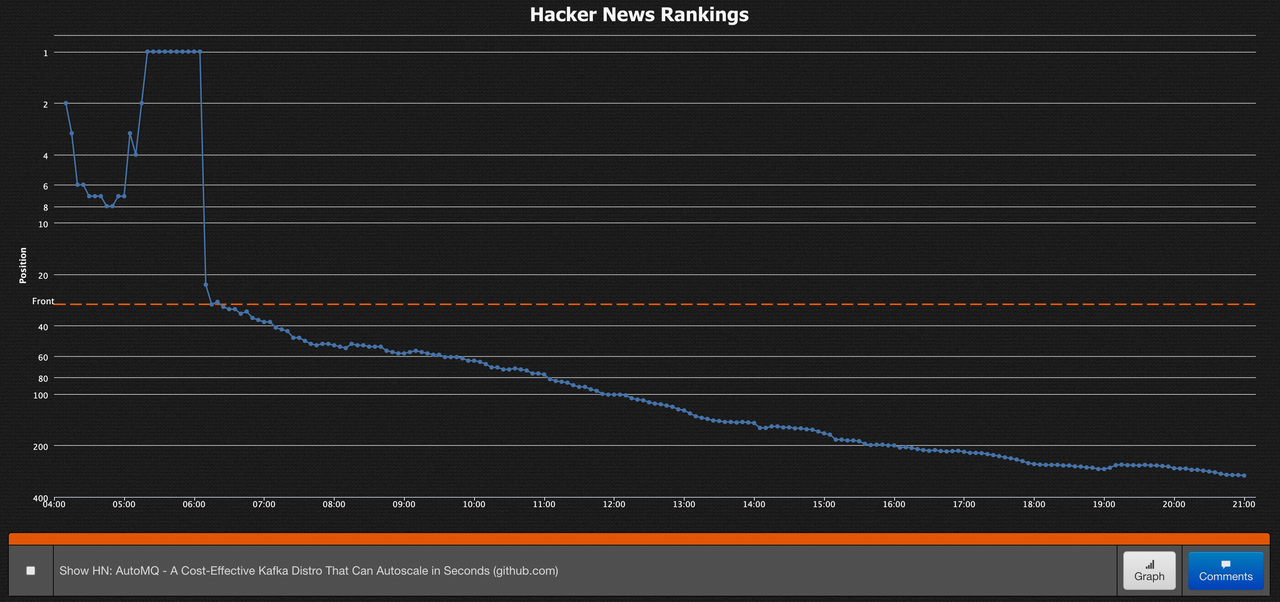
AutoMQ 第一次被大量海外开发者看见,是在 Hacker News。2024 年 4 月,AutoMQ 以 Show HN: AutoMQ - A Cost-Effective Kafka Distro That Can Autoscale in Seconds 发布,并一度登上 Hacker News 榜首。
这次讨论让我们第一次真切感受到,海外开发者对 Diskless Kafka 这个方向有很强的兴趣。评论区集中在标准 Kafka 客户端兼容、写入确认、WAL 故障恢复、benchmark 数据等问题上。这些都是真实 Kafka 生产使用里绕不开的问题。那一次,HN 带来了流量,也带来了很具体的工程反馈。
HN 之后,AutoMQ 也持续把 Diskless Kafka 的工程实践带回 Apache Kafka 社区。我们希望分享过去几年围绕共享存储、云原生弹性和 Kafka 兼容性形成的架构思考。
2025 年,AutoMQ 提出 KIP-1183: Unified Shared Storage。这个提案进入 Apache Kafka 社区后,很快形成了一轮关于共享存储架构的讨论,多位 Apache Kafka Committer / PMC 成员参与其中。讨论聚焦在 shared-storage 是否应该进入 Kafka、Stream 抽象如何设计,以及它与 ISR 和本地存储引擎如何长期共存。
这个 KIP 讨论的是 Kafka 如何面向对象存储、文件存储、块存储等共享存储服务,抽象出统一的共享存储层。它延续了 AutoMQ 一直推动的方向,让 Kafka 保留成熟的协议和生态,同时让存储层更好地利用云基础设施已经提供的持久性、弹性容量和按需付费模型。
到 2025 年 Confluent Current London,这些线上讨论变成了面对面的技术交流。Current 是 Kafka 生态里重要的行业会议之一,现场聚集了很多长期使用和建设 Kafka 的工程团队。我们带到伦敦的,是 AutoMQ 的开源实现、KIP-1183、海外客户的生产实践,以及过去几年围绕 Diskless Kafka 做出的工程选择。
在现场,我们和 IBM、Apple、OpenAI 等多个 Kafka 技术团队交流了 AutoMQ 低延迟 Diskless Kafka 的架构设计。大家直接讨论几个工程问题:持久数据为什么可以从 Broker 本地盘迁移到共享存储,Kafka 客户端和周边生态如何保持兼容,Broker 故障恢复和扩缩容时怎样减少数据搬迁。在这样的技术交流里,AutoMQ 的 Diskless Kafka 路线和低延迟共享存储实现收到了很积极的反馈。我们也看到,全球一线企业的 Kafka 团队同样在探索下一代 Kafka 存储架构,评估如何从 Broker 本地盘走向 Diskless / shared-storage 形态。在云上和 AI 应用带来的实时数据需求下,本地盘、多副本复制和大规模数据搬迁,已经成为很多团队绕不开的负担。

AutoMQ 的 Diskless Kafka 路线
AutoMQ 的技术创新之所以得到这么多开发者关注和认可,原因很直接:Apache Kafka 以 Broker 本地磁盘为中心的传统架构,已经越来越难满足云和 AI 时代对成本、弹性和实时数据处理的要求。
Kafka 的协议、语义和生态仍然很成熟,需要重新设计的是存储模型。HN 评论、KIP-1183 和伦敦现场交流反复回到同一个问题:Kafka 要继续适配云上和 AI 时代的实时数据需求,Broker 是否还应该和持久数据绑定在一起?
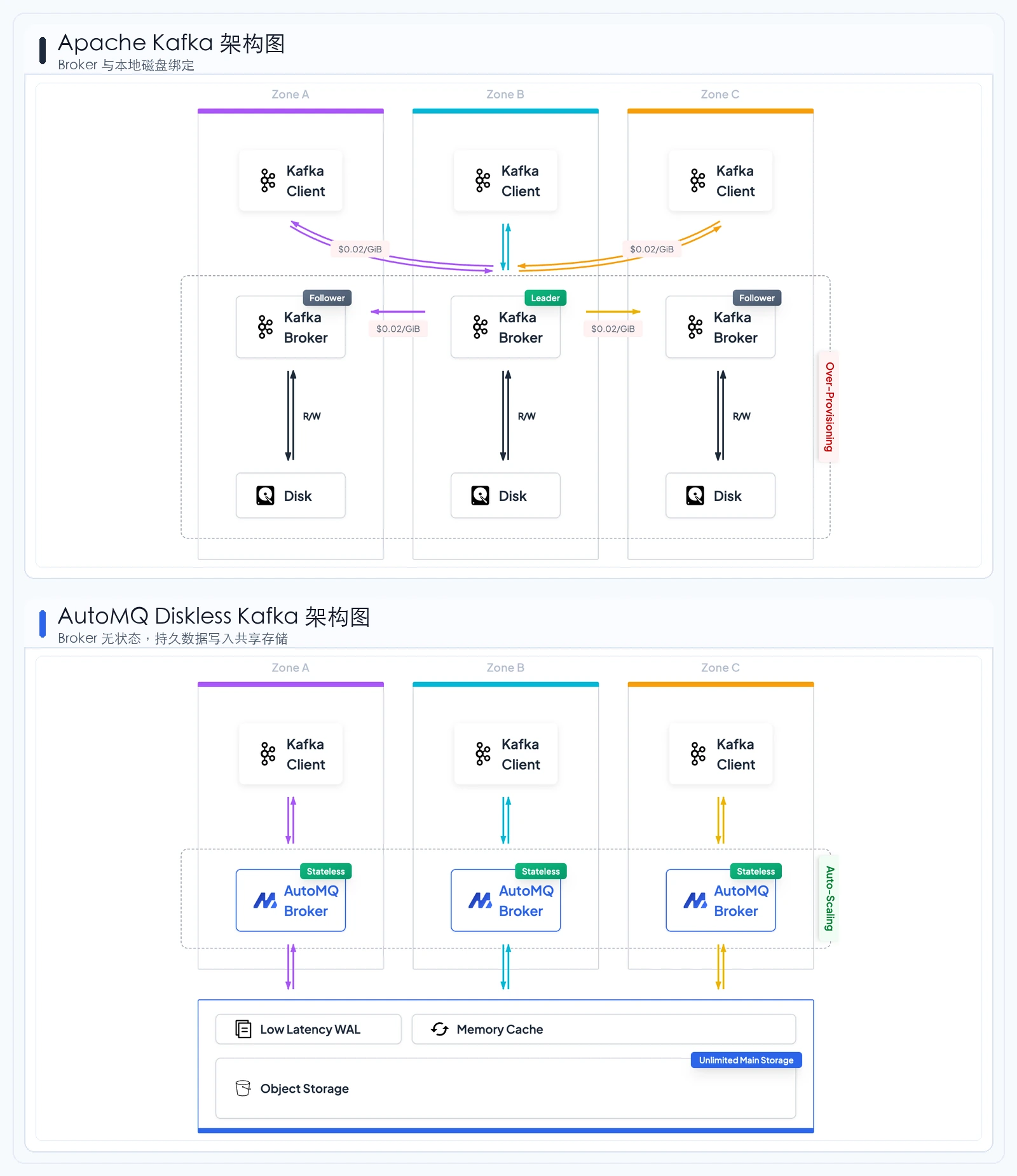
传统 Kafka 的 shared-nothing 架构在数据中心时代非常合理:每台 Broker 管理自己的本地磁盘,Partition 数据通过 ISR 在多个 Broker 间复制,系统用应用层副本来获得可靠性。那个时代,机器之间复制数据通常不会单独出现在云账单里,存储和计算绑定在同一台物理机上,也是一种简单直接的工程选择。
到了云上,这套前提变了。云基础设施已经把持久性、跨可用区冗余和弹性容量做成了标准服务,但传统 Kafka 仍然按数据中心时代的方式运行。结果是,团队在云上同时承担了几类重复成本:
- 存储层面,云盘已经提供持久性,传统 Kafka 仍然会把同一份 Partition 数据复制到多个 Broker。用户要准备多份云盘容量,也要为副本写入付出成本。
- 网络层面,Broker 之间跨可用区复制 Partition 数据,会形成持续的跨 AZ 流量成本。
- 运维层面,扩缩容除了增减计算节点,还要搬迁大量 Partition 数据,重平衡过程可能持续数小时。
- 资源层面,计算、存储和网络被绑在 Broker 上,团队很难只为某一类资源独立扩容。
AutoMQ 的 Diskless 架构把持久数据放到共享存储,让 Broker 成为无状态计算节点,同时保留 Kafka 的协议、语义和生态。Broker 故障替换或扩缩容时,系统主要切换元数据和流量归属,不再为每一次容量变化搬迁大量 Partition 数据。
对企业用户来说,架构升级不能让业务代码和上下游生态重来。AutoMQ 基于 Apache Kafka 代码库,在接入层保留 Kafka 的协议语义和客户端生态,在存储层用 S3Stream 和共享对象存储替代传统本地 LogSegment。客户端、Connect、Flink、Schema Registry 和运维习惯都可以延续。
下面这张图比较了 Apache Kafka 和 AutoMQ 在架构上的差异。
持续技术创新与全球化
Diskless Kafka 能不能成立,最终要看生产环境。AutoMQ 最早的一批高强度反馈来自国内客户。
在国内推进 AutoMQ,更像本土作战。相比海外市场,国内客户给了我们更早的初始信任,也愿意更早把关键 Kafka 负载交给 AutoMQ;国内互联网业务的数据规模、链路复杂度和高峰流量,又让产品很快面对真实生产压力。稳定性、Kafka 兼容性、迁移工具、扩缩容过程、故障定位和运维诊断,这些能力都在一线场景里被反复打磨。
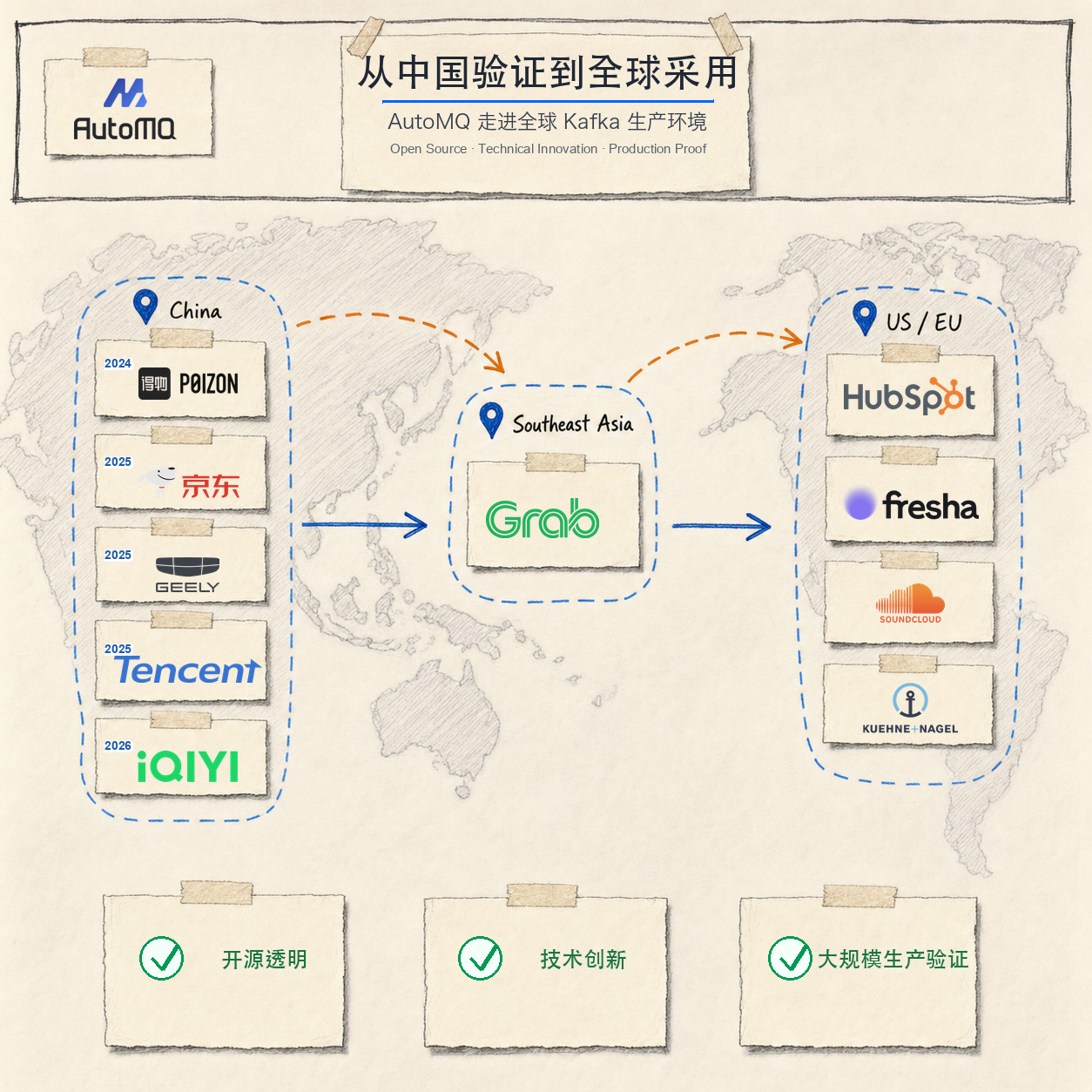
2024 年,得物可观测平台大面积投产 AutoMQ。2025 年,京东、腾讯在多条业务线使用 AutoMQ,吉利汽车等企业也在生产场景中采用 AutoMQ。2026 年,爱奇艺也开始在业务场景中采用 AutoMQ。这几年的国内落地,把 AutoMQ 放进了不同类型的高强度场景,也打磨了内核、迁移和运维能力。京东、腾讯、吉利汽车这样的中国企业服务着大规模用户和复杂业务,它们的生产验证,让海外客户理解 AutoMQ 时多了一层可参照的工程背景。
进入海外市场后,信任要重新建立。对一家中国背景的基础软件公司来说,海外客户的评估会更谨慎:团队是否理解 Kafka,架构设计能否解释清楚,代码能否通过客户自己的测试,生产问题出现后能否定位和修复。AutoMQ 采用 Apache 2.0 License 开源,让用户可以直接读代码、跑测试、看实现细节,也能沿着 issue、PR 和公开设计理解系统为什么这样工作。
开源之外,我们也持续把技术细节讲出来。AutoMQ 定期在国内外分享分区秒级迁移如何实现,基于对象存储的流存储引擎如何工作,为什么可以做到 100% Kafka 兼容,以及 Diskless Kafka 和共享存储架构在云上的取舍。这些分享让海外开发者看到 AutoMQ 的工程方法和技术判断,看到这个新架构名字背后的具体实现。代码、文章、演讲、社区讨论和生产验证叠在一起,才让一个陌生项目进入工程团队的选型和架构评估。
带着这些积累,AutoMQ 开始从国内走向东南亚和欧美。新加坡国民级出行应用 Grab、美国 CRM 领导者 HubSpot、英国美容健康领导者 Fresha、德国音乐流媒体巨头 SoundCloud、瑞士全球物流领导者 Kuehne + Nagel,都在各自的 Kafka 生产场景里采用了 AutoMQ。这些客户分布在不同地区和行业,面对的数据链路也不一样。AutoMQ 走到这些场景里,靠的是开源透明、Kafka 兼容性、Diskless 架构带来的弹性和成本优势,也靠国内大规模生产场景积累下来的工程能力。
Fresha 是其中一个公开留下工程记录的例子,也让我们能直接听到终端客户自己的声音。它是英国美容、健康与自我护理行业的 SaaS 平台,数据平台需要把大量 PostgreSQL CDC 事件写入 Kafka,再由 Snowpipe、Flink、StarRocks 等系统消费。它的技术负责人 Anton Borisov 发布过两篇公开文章,记录团队的迁移过程,也写下了他对 AutoMQ 开源透明和持续创新的评价:
With AutoMQ, we can trace how the system works, why certain choices were made, and where it can improve. That transparency: messy, evolving, but real is what keeps progress visible.
That’s why I have a soft spot for AutoMQ as they don’t just build the future, they open it up for everyone to build together, yet continuing pushing the frontier with new ideas and features.
— Anton Borisov, Fresha
工程团队可以沿着代码、设计和公开讨论理解 AutoMQ,追踪系统如何工作,判断架构选择为什么这样做,也能看到后续还可以在哪里继续改进。对基础软件来说,这种透明性会直接影响工程团队是否愿意继续评估、迁移和长期使用。
最终,AutoMQ 能进入 Grab、HubSpot、Fresha、SoundCloud、Kuehne + Nagel 等海外生产环境,靠的是几件事一起发挥作用。开源带来的透明性、持续技术分享建立的理解和信任、国内大规模生产场景提供的验证,以及 Diskless Kafka 架构本身带来的成本、弹性和运维价值,放在一起,才让海外客户愿意把 AutoMQ 放进真实 Kafka 链路。
展望未来
谢谢每一位 Star 过 AutoMQ、试用过 AutoMQ、提过 issue、贡献过代码、给过反馈的开发者。也谢谢那些愿意把 AutoMQ 放进真实生产环境的客户。
10K Star 是个节点。我们会庆祝它,也会很快回到日常工作里:继续写代码、修 issue、打磨文档、服务客户、和社区讨论 Kafka 在云上的下一步。
接下来,AutoMQ 会继续保持 Kafka 兼容和开源透明,继续打磨低延迟 Diskless Kafka 架构,让更多企业可以在云上运行关键 Kafka 负载时,少一点本地磁盘和数据搬迁带来的负担。面向实时分析、数据湖和 AI 应用带来的新需求,我们也会继续推进 Table Topic 等能力,让 Kafka 数据更直接地进入下一代数据基础设施。
回到那条 Star History 曲线,里面的每一个拐点,背后都有开发者的尝试、客户的验证、伙伴的转介绍和社区的讨论。下一段曲线,希望和更多开发者、用户和生态伙伴一起写下去。
如果你也在评估 Kafka 的云原生化、成本优化或弹性扩缩容,可以从 AutoMQ 开源仓库开始,直接阅读代码、运行测试环境,验证 Diskless Kafka 是否适合你的生产工作负载:在 GitHub 上查看 AutoMQ。