
2026 年 1 月 2 日,Grafana 在官方博客介绍了 Mimir 的新一代架构:Mimir’s next-gen architecture—Kafka in the middle, object storage underneath, and a whole lot less coupling。标题里的三个短语给出了这次调整的线索:Kafka 放到中间,对象存储在下面,组件之间少一点互相牵制。
Grafana 在文中回到 classic architecture 里的一个老问题:ingester 同时承接写入和最近数据查询。它保存刚写入的 sample,也响应查询路径对 recent data 的请求。只要 heavy query 把 ingester 压满,write path 就可能被一起拖慢。
Mimir 3.0 推荐的 ingest storage architecture 把写入路径的边界移到了 Kafka。Grafana 文档里的说法很直接:write path ends at Kafka。
具体到流程上,distributor 不再把 sample 直接推给 ingester,而是写入 Kafka 或 Kafka-compatible ingest storage。Kafka 确认持久化之后,Mimir 再向客户端确认写入;ingester 从 Kafka partition 持续消费 sample,供查询路径读取。
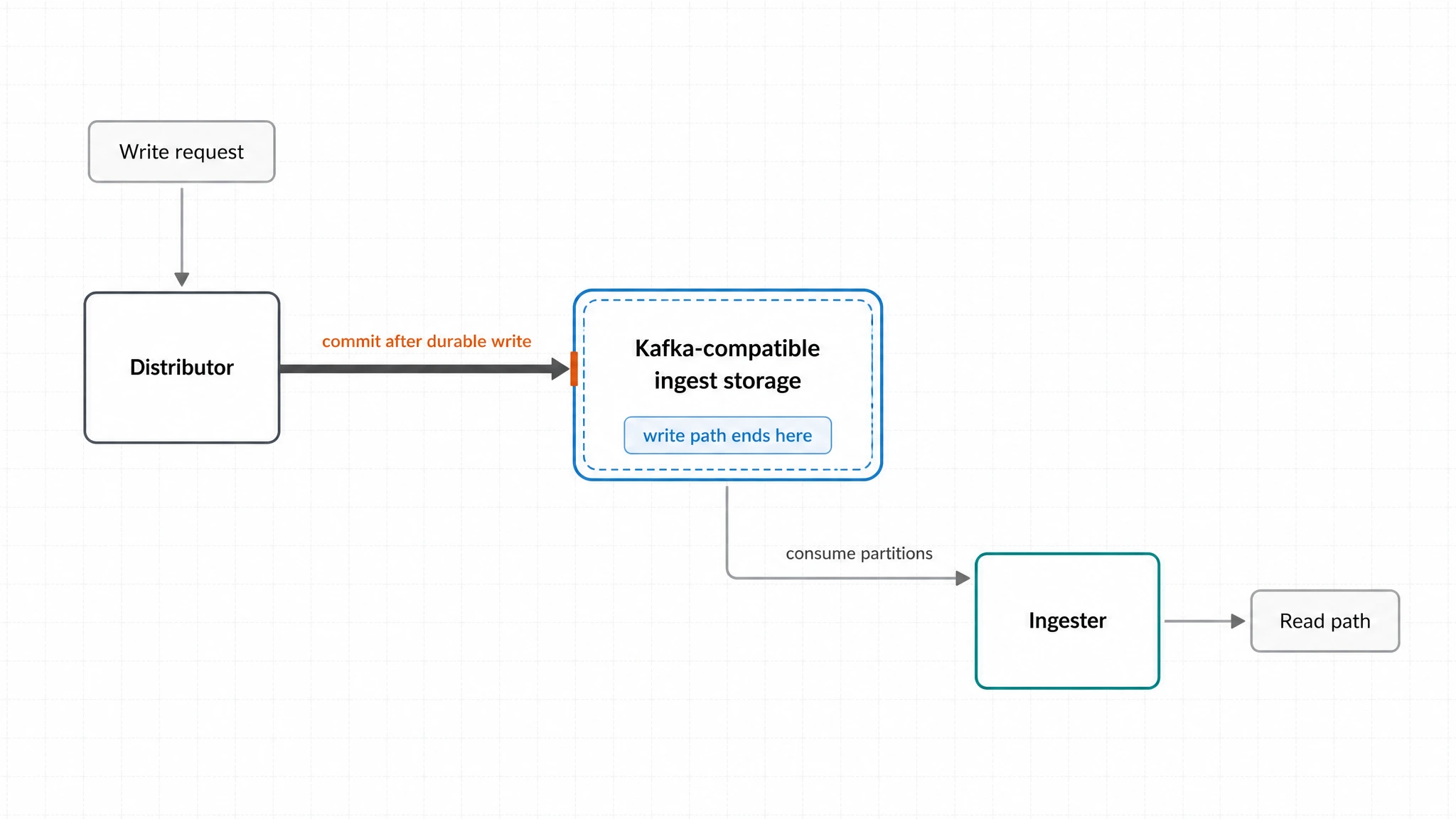
Kafka 因此变成了写入路径的提交边界,不再只是 Mimir 旁边一个“能接上就行”的依赖。自托管团队评估 Mimir ingest storage 时,话题也会从 Kafka API 兼容,继续走到这层 Kafka 怎么运行:数据放在哪里,扩容时要不要搬 partition,跨 AZ 读写和复制会不会被云厂商按流量计费,Kubernetes 里怎么替换节点。
云厂商通常会对跨 AZ 数据传输单独计费。AWS 会把同 Region 不同 Availability Zone 之间的数据传输计入 regional data transfer;Google Cloud 也对同一区域不同 zone 之间的数据传输列出计费项。Metrics ingest 是数据密集型场景,producer 写入、broker 间复制、consumer 读取一旦跨 AZ,都会把持续流量带进账单。
过去一段时间,我们在 AutoMQ 客户交流中也看到类似方向:越来越多自托管 Mimir 团队开始把 AutoMQ 放到 Mimir ingest storage 前面的 Kafka-compatible 层。Mimir 用 Kafka 拆开读写路径;AutoMQ 用对象存储拆开 Kafka broker 和持久化数据。两件事叠在一起,Mimir 得到的是 Kafka 接入面,同时不用把整条 metrics pipeline 又带回重本地磁盘、重数据搬迁的 Kafka 运维模型。
这也是 AutoMQ 会进入 Mimir 选型讨论的原因。对自托管团队来说,Mimir 需要一层适合 ingest path 的 Kafka-compatible backend:Kafka 语义稳定,持久化状态不绑 broker 本地盘,扩缩容不依赖大量数据搬迁,multi-AZ 成本可控,Kubernetes 运维入口熟悉,并且可以开源自建。
Mimir 为什么要把 Kafka 放到中间
Mimir ingest storage architecture 处理的是 classic architecture 里 ingester 过重的问题。指标系统的写入和读取压力本来就不同步:写入侧要持续接收 sample,读取侧要服务查询,还要面对高基数 label、突发流量和不均匀的查询模式。当这些压力都落到 ingester 上,系统扩展和故障恢复都会变得更难。
Kafka 在新架构里承担两个动作。第一,distributor 把写入请求切到 Kafka topic 的多个 partition,并等待 broker 确认这些记录已经持久化。第二,ingester 从 partition 里持续消费数据,把 sample 放进内存状态,再服务查询。write path 不再等 ingester 参与 quorum;read path 上的 heavy query 也不该再直接拖住刚进入系统的写入请求。
自托管团队因此要把 Kafka 当作架构决策来评估。既然 Mimir 的写入确认来自 Kafka,这层 Kafka 的存储和扩缩容方式就会影响整条 ingest pipeline。只验证客户端能连通 Kafka 还不够,团队还要看它在生产里怎么处理 broker 替换、partition placement、跨 AZ 流量和持续写入。
Mimir ingest storage 需要怎样的 Kafka 层
Metrics ingest 很少按计划变化。它可能连续几周都很平稳,也可能因为一次服务发布、一次事故、一次 retention 调整,突然出现更高的 series cardinality 或 scrape 压力。问题出现时,团队最不想处理的往往就是 broker 磁盘、数据重平衡和跨 AZ 复制成本。
传统 Kafka 通过 broker 本地磁盘和 broker 间复制来保证持久性。在云上跑 multi-AZ Kafka,这通常意味着每个 broker 都有自己的本地持久化数据;集群扩容时,partition 数据迁移和负载重平衡也会进入流程。写入量越大,这些操作越容易和生产流量争抢资源,存储复制和跨 AZ 流量也越容易进入账单。
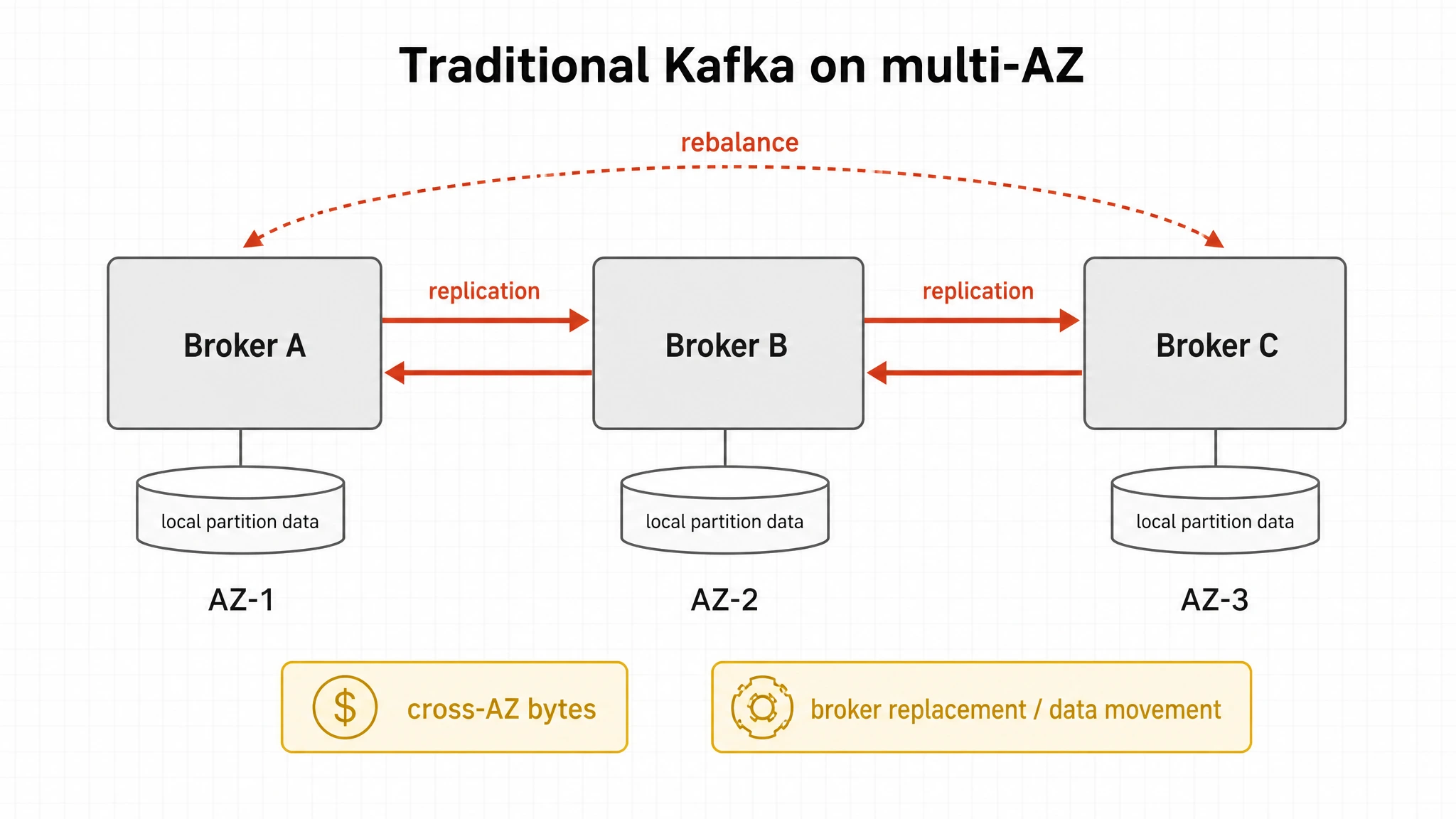
Mimir 本身已经把 metric block 的长期持久化放到了对象存储。如果 Kafka 在它前面再保留一套很重的本地磁盘存储,平台团队就要同时照看两套状态:对象存储里的 Mimir block,以及绑定在 broker 本地磁盘上的 Kafka partition。这个架构可以跑,但它和 Mimir 新架构减少状态耦合的方向并不完全一致。
评估这层 Kafka 时,吞吐和 API 兼容只是起点。Kafka 放在 Mimir ingest path 上以后,存储模型、扩缩容方式、multi-AZ 成本、Kubernetes 运维入口和开源自建路径,都要一起进入选型。
为什么 AutoMQ 是 Mimir ingest storage 的最佳组合
Mimir 把 Kafka 放进 ingest storage 之后,这层 Kafka 要接住 distributor 的持续写入,给 ingester 留出可追赶的日志,还要在服务扩容、故障恢复和查询压力变化时保持写入路径稳定。自托管团队需要确认两件事:Mimir 继续按 Kafka 模型工作;Kafka 层不把本地磁盘、数据搬迁和扩缩容压力带回写入路径。
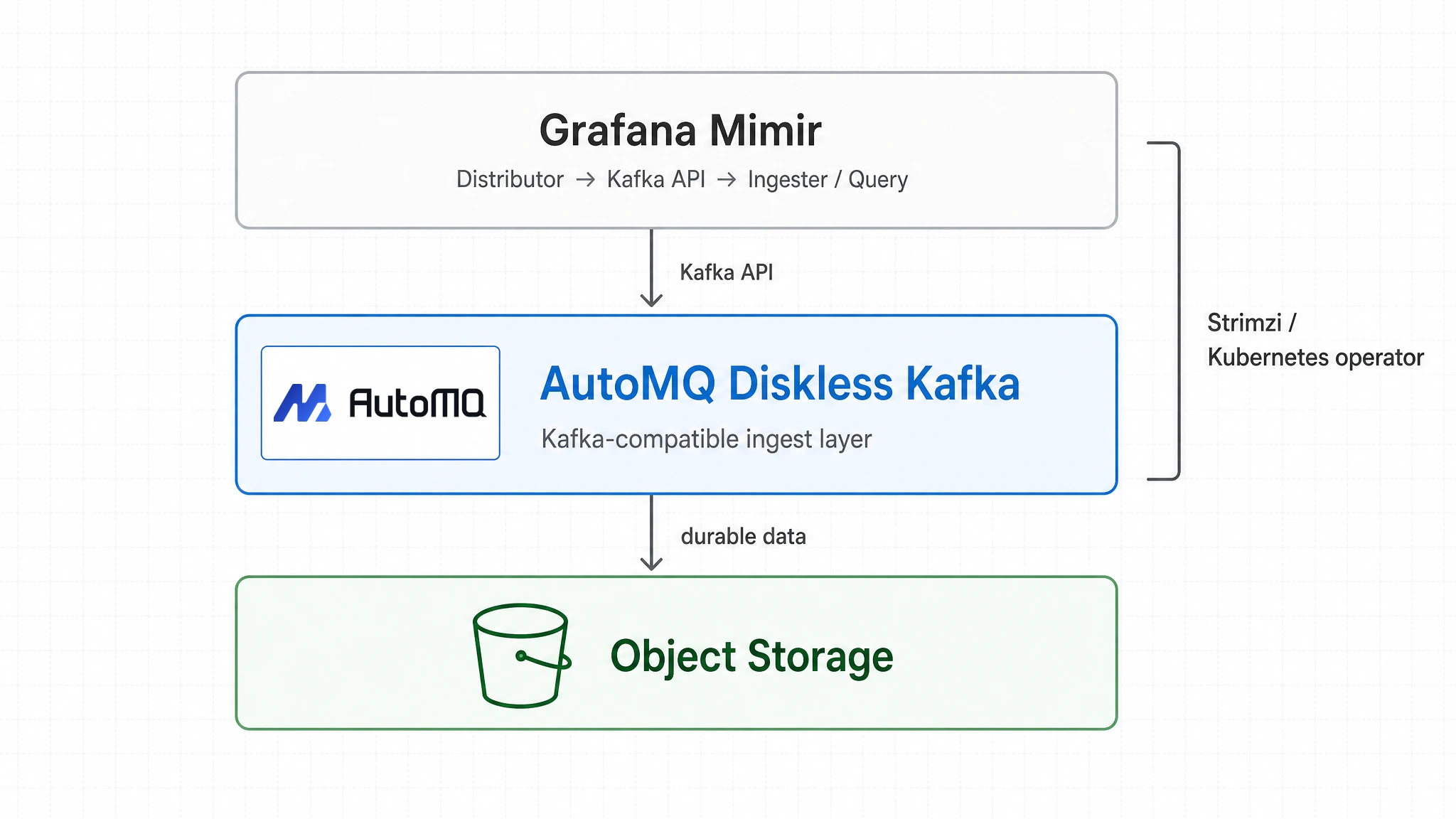
AutoMQ 放在这里,Mimir 看到的仍然是 Kafka:distributor 写 topic,ingester 通过 consumer group 消费。变化发生在 Kafka 下面一层:AutoMQ 保留 Kafka 协议和计算层,把 Kafka 的持久化数据从 broker 本地磁盘移到共享对象存储。
Mimir 对这层 Kafka 的要求,可以直接映射到 AutoMQ 的几项能力:
| Mimir 对 Kafka 层的要求 | 为什么对 Mimir 重要 | AutoMQ 怎么对应 |
|---|---|---|
| Kafka API 和协议语义稳定 | Distributor 写入 Kafka,ingester 通过 consumer group 消费数据并持久化消费进度;这条路径不能因为替换 ingest backend 而改变。 | AutoMQ 官方采用 100% Kafka API / protocol compatible 的兼容性声明,保留 Kafka 客户端、工具和生态接入方式。 |
| 持久化边界不再绑定 broker 本地盘 | Kafka 已经是 write path 的提交边界。如果持久化数据仍然绑在 broker 本地磁盘上,Mimir 只是把状态压力从 ingester 往下移了一层。 | AutoMQ 是 Diskless Kafka,broker 不再把持久化数据绑定到本地磁盘,数据进入共享对象存储。 |
| 高吞吐 metrics ingest 下的弹性 | Series cardinality、scrape 压力和服务接入规模都会变化;扩容不应该变成一次 partition 数据搬迁项目。 | Broker 更接近计算节点,扩缩容更多是在调整归属关系和流量,不再等价于大规模 partition 数据迁移。 |
| 可控的 multi-AZ 成本结构 | 高吞吐 metrics ingest 会放大存储复制和跨 AZ 流量。Kafka 进入写入路径后,这部分成本会跟着 ingest 规模一起增长。 | 对象存储改变了传统 broker 本地盘和 broker 间复制带来的成本结构,让持久化数据不再围绕 broker 本地副本展开。 |
| 更轻的 Day-2 运维 | Broker 替换、扩容、partition rebalance 和本地数据恢复不应该反复打断 Mimir write path。 | 持久化数据位于共享对象存储,broker 替换不再强依赖本地 partition 数据,扩缩容也不再等价于搬迁大量本地数据。 |
| Kubernetes 上的熟悉运维模型 | 很多自托管 Mimir 团队已经在 Kubernetes 上运行观测系统,Kafka ingest backend 也应该适配 operator 驱动的运维方式。 | AutoMQ 支持 Strimzi 部署,团队可以继续使用 Kafka-native 的运维入口。 |
| 开源、自托管、可审计 | 选择 Mimir 的团队往往希望保留开源、自托管和可审计的基础设施路线,Kafka 层也应该符合这个取向。 | AutoMQ Open Source 采用 Apache 2.0 许可;Mimir + AutoMQ 可以组成一套面向自托管观测平台的开源技术栈。 |
这些约束会同时出现在 Mimir ingest path 上。写入路径需要 Kafka 语义,存储层需要减少 broker 本地状态,容量变化不能变成数据迁移项目,成本和运维复杂度不能被 broker-local replication 放大,Kubernetes 团队还要保留熟悉的 operator 工作流。
AutoMQ 把这些要求收在一个存储模型里:保留 Kafka 接入面,把持久化数据放进对象存储,让 broker 更接近计算节点。Mimir 不需要理解 AutoMQ 内部的存储引擎,也不需要放弃已经采用的 Kafka 模型;平台团队则可以把 metrics ingest layer 的成本、弹性和 Day-2 运维放在同一个架构里处理。
用 Mimir 和 Diskless Kafka 构建现代化可观测基础设施
如果你正在采用 Mimir ingest storage,Kafka 已经是 observability write path 的一部分。把它当作普通依赖,会低估它对系统行为的影响。Kafka 层决定 write path 如何吸收压力、集群能多快扩缩容、multi-AZ 成本如何增长,以及存储运维会在多大程度上进入平台团队的日常工作。
Mimir 3.0 的新架构已经这样设计:用 Kafka-compatible ingest storage 拆开写入和读取,用对象存储承接长期 metric block。AutoMQ 接在这条路径上,把 Kafka 这一层也推向同样的方向:应用层保留 Kafka contract,持久化数据进入对象存储,broker 不再背着大量本地 partition 数据移动。
这样组合起来,Mimir 负责 metrics 的写入、读取和长期存储,AutoMQ 负责 Kafka-compatible ingest layer 的持久化和弹性,Strimzi 保留 Kubernetes 上熟悉的 operator workflow。对自托管团队来说,这条路线的好处很直接:Kafka 接入面不变,Diskless storage 降低本地磁盘耦合,成本和运维复杂度一起向对象存储模型收敛。
如果你正在评估 Grafana Mimir 的 Kafka-compatible ingest storage,可以注册 AutoMQ Cloud,在自己的环境里跑一套 Kafka-compatible、Diskless 的 AutoMQ 架构:注册 AutoMQ Cloud。