2026 年 5 月,AWS US-EAST-1 的一次可用区(AZ)故障让 Coinbase 的交易服务短暂中断。The Stack 的事故梳理 里有一个值得 Kafka 平台团队关注的细节:Coinbase 的 Amazon MSK 集群已经按照 Kafka 最佳实践做了多可用区、多副本部署,但故障发生后,AWS MSK 没有按预期完成故障转移。
从 Coinbase 2021 年的 MSK 架构分享看,这套集群的基础配置并不薄弱:跨多个 AZ 的 30 个 broker,3 AZ 部署,Replication Factor=3,min.insync.replicas=2。这些都是 Kafka 高可用设计里的关键项。这个案例提醒我们,即使副本参数看起来完备,也不能保证 Kafka 集群在真实故障中一定完成恢复。Kafka 可用性不是把几个副本参数调对就结束,而是一套覆盖故障转移、客户端重连、容量承接、数据追赶、消费进度和下游恢复的系统工程。其中任何一个环节出问题,都可能导致高可用和容灾恢复无法按照预期执行。
接下来,我们将继续拆解 Kafka 可用性在真实故障恢复中的挑战,并结合 AutoMQ 的高可用与容灾恢复设计,理解这套系统工程应该如何做得更稳。
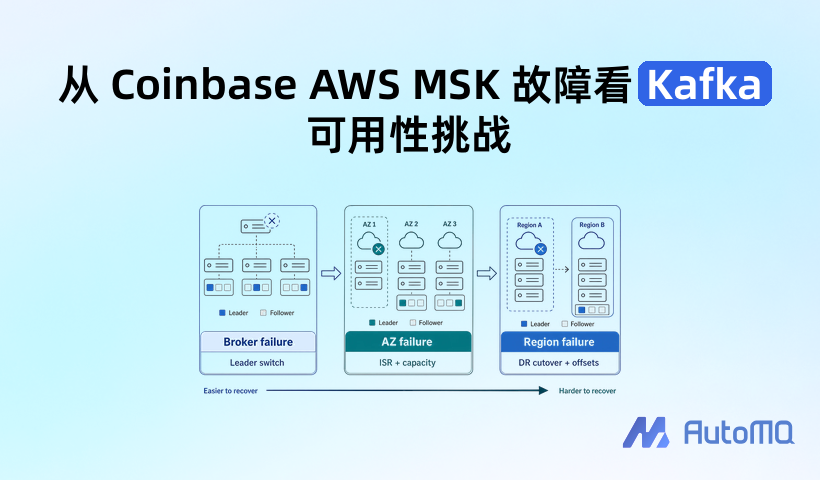
单集群故障域:难点在接管和承接
在单集群里,broker、节点或一个 AZ 出问题时,Kafka 要做的是让服务在同一个集群内继续提供服务:确认 ISR,切换 partition leader,刷新客户端 metadata,让 producer 和 consumer 继续推进。Replication Factor 决定副本数量,min.insync.replicas 决定写入成功所需的最小同步副本数;但它们只覆盖“数据是否有足够副本”这一部分。一次恢复能不能落地,还要看 leader 切换是否顺利、客户端是否及时重连、剩余 broker 是否有容量、落后的副本能否追上。
传统 Kafka 的恢复会在这里变重,是因为 broker 同时承担计算和本地持久化职责。每个 partition 的数据被复制到多个 broker,本质上是把同一份日志维护在多个本地磁盘上。这个模型在数据中心时代非常合理,也支撑了 Kafka 多年的生产实践;但到了云上,它会和对象存储等跨故障域持久化能力形成重叠,并让故障后的副本恢复、扩容和 partition reassignment 都可能涉及数据移动。
这会直接影响故障后的可用性。一个 broker 下线后,leader 可以切到其他副本,但剩余 broker 必须同时承担更多读写流量;如果集群本来接近饱和,业务仍可能遇到延迟、限流或客户端错误。一个 AZ 出问题时,剩余 AZ 里不仅要有可用副本,还要有足够 ISR、健康 leader 和计算容量。可用性恢复不是某个故障转移动作完成就结束,而是服务能否稳定承接故障后的流量。
AutoMQ 对单集群高可用的切入点,就是减少 broker 和本地持久化数据之间的绑定。AutoMQ 保持 Kafka 协议和语义兼容,但把传统 Kafka 绑定在 broker 本地磁盘上的存储层迁移到共享对象存储。Broker 更接近无状态计算节点,持久数据由共享存储承担;broker 故障首先是计算节点损失,不再是某批本地 partition 副本跟着失效。
在 AutoMQ 的 Shared Storage 架构下,单集群故障恢复可以避开一类很重的工作:先把完整 partition 副本复制到新节点。传统 Kafka 里,leader 切换依赖 ISR 状态;后续为了恢复副本数或重新均衡容量,partition reassignment 往往还要搬数据。在 AutoMQ 里,partition 的持久数据不绑定在故障 broker 的本地盘上。故障发生后,健康 broker 可以基于共享存储中的持久数据恢复服务状态,然后接管该 partition 的读写。因为不需要等待完整副本搬迁,健康 broker 或新增 broker 可以更快参与调度和流量分摊,集群容量恢复也更快。
跨地域容灾恢复:难点在一致性和 RTO
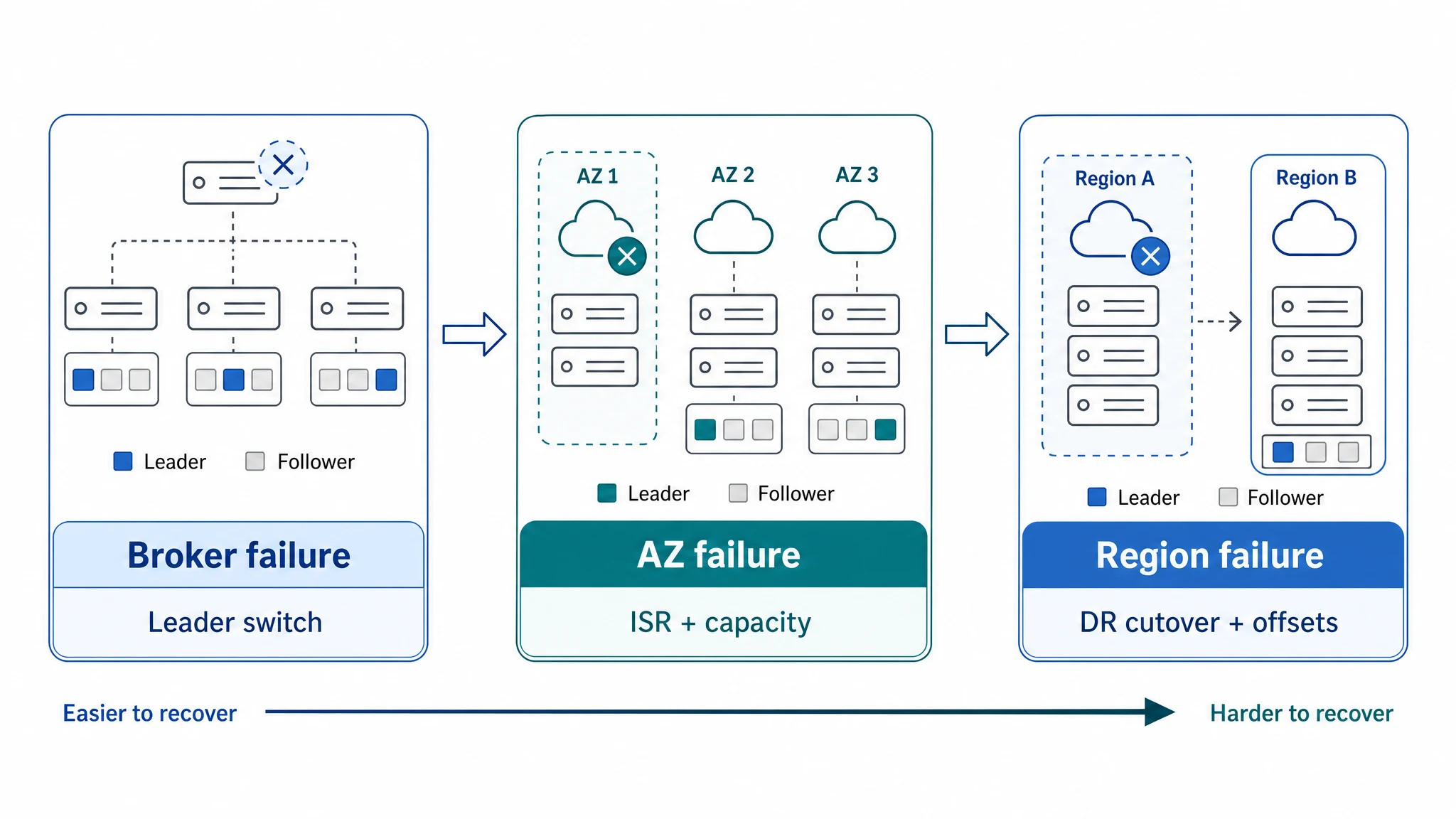
单集群高可用做得再好,边界通常也在一个 Region 内,最多覆盖 broker、节点或 AZ 故障。故障扩展到地域级,或者整个集群因为错误发布、元数据损坏、网络隔离等原因无法继续承载业务时,平台团队一般会准备一套独立的容灾集群:主集群承载线上读写,容灾集群通过复制链路持续接收数据,必要时提升为新的业务入口。
传统 Kafka 双集群容灾恢复主要有两个挑战:一是一致性恢复,二是把 RTO 控制在足够短的时间内。
先看一致性恢复。数据可以通过 MirrorMaker 2、Kafka Connect 或自研链路持续复制到容灾集群,但切换时,consumer group offset、Flink checkpoint、复制延迟和回切对账都要对得上。传统基于 MirrorMaker 2 的异步复制可以解决数据复制问题,但容灾集群落后多少、应用应该从哪里继续、下游状态是否能和 Kafka offset 对齐,都会影响恢复质量。复制链路解决的是数据到达问题;一致性恢复解决的是业务能不能从正确位置继续。
另一个问题是 RTO:故障发生时,平台团队能否尽快恢复业务入口,提供接近无感的秒级恢复体验。传统基于复制链路的容灾恢复,切流和提升通常是人工操作,涉及 DNS 切换、客户端重连、应用重启等步骤,RTO 往往在分钟级甚至更长。
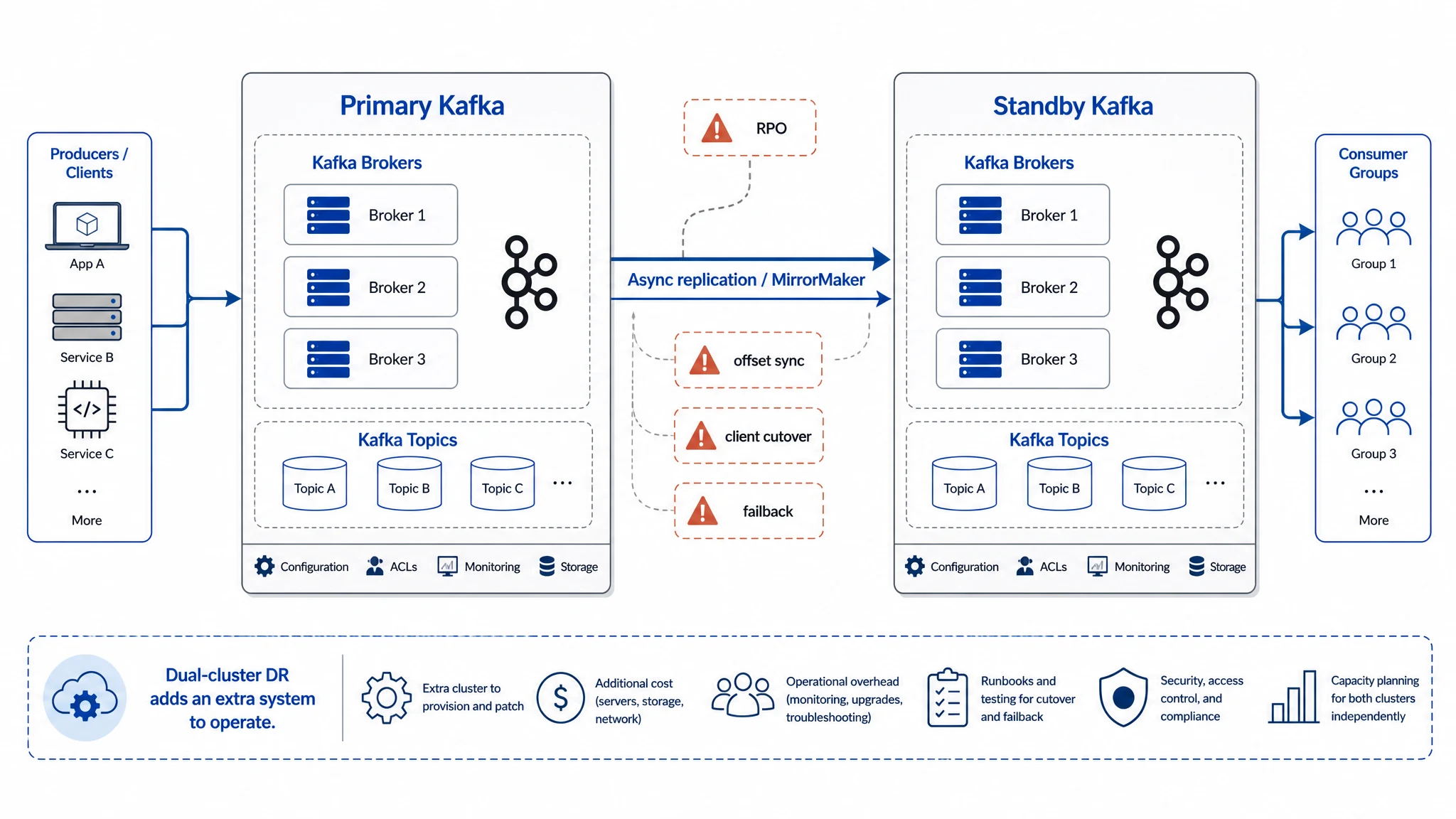
为了解决 Kafka 容灾恢复中的这些挑战,AutoMQ 提供了 Async Kafka Linking DR 容灾恢复能力。该能力同时面向两个目标:秒级 RTO 和一致性恢复。
主集群继续承载低延迟写入,AutoMQ Linking 通过字节级复制将数据异步复制到独立容灾集群,保持源集群和目标集群的 offset 一致。等到需要容灾恢复时,依赖 Metadata-only Proxy 的自动切流能力,业务可以无感切到容灾集群,并让 consumer group 和 Flink 作业从对齐后的检查点位置继续恢复。
AutoMQ 通过 Metadata-only Proxy 为主集群和容灾集群提供一致的接入点;当故障发生时,可以自动将容灾集群晋升为主集群,保证业务持续可用,并提供秒级 RTO 的恢复体验。Proxy 负责 metadata requests、placement decisions 和 failover routing,生产和消费流量仍然直连 AutoMQ Brokers,是一个为容灾恢复场景设计的轻量组件。
小结:把可用性拆成三层看
从 Coinbase 事件回看 Kafka 可用性,参数是否配置正确只是起点。平台团队还需要继续追问三件事:单集群内服务能不能快速接管,接管后容量能不能承载流量,跨地域故障时业务能不能在容灾集群里从正确位置恢复。
| 层级 | 解决的问题 | AutoMQ 的切入点 |
|---|---|---|
| 高可用 | 单集群故障时,服务能否接管、数据是否安全 | Shared Storage 架构、健康 broker 接管 partition 读写、controller 驱动的故障转移 |
| 容量恢复 | 接管后,剩余计算资源能否稳定承接流量 | 无状态 broker、快速扩容、Self-Balancing |
| 容灾恢复 | 地域故障、集群异常或需要切到容灾集群时,业务能否快速切换并从正确位置恢复 | 多集群隔离、Metadata-only Proxy、AutoMQ Linking、offset 对齐、Async Kafka Linking DR |
这也是 AutoMQ 对 Kafka 可用性的基本思路:把一部分恢复复杂度提前消化在架构里。Shared Storage 架构减轻单集群高可用恢复路径,快速扩容帮助集群恢复容量,Async Kafka Linking DR 则在跨地域容灾中提供秒级 RTO 和一致性恢复。如果你对 AutoMQ 的集群高可用和跨地域容灾能力感兴趣,欢迎联系我们,一起评估你的 Kafka 工作负载适合怎样的分层可用性架构。