
本文转载并翻译自 Nicoleta Lazar 发表在 Fresha Data Engineering Medium 的原文。

大约一年前,在 Confluent Current 2025 期间,Aiven 团队公开了他们围绕新 KIP-1150 所做的工作,也就是 Diskless Kafka:一个不再依赖本地磁盘来提供持久化和耐久性,而是利用云存储来提供这些保障的新版本 Apache Kafka。它的目标是降低运维成本,同时让整个 Kafka 集群更具弹性、更易扩展,并能更快完成 rebalance。
从那时起,很多事情已经发生变化,包括最初方案被整体重构为新的 Diskless 2.0 方案。我们也曾在上一篇文章中介绍过这次 Kafka 架构重塑背后的主要思想:Broker 变得无状态、可随时丢弃。
对 Fresha 来说,时机再合适不过了:我们当时已经在评估 AWS MSK 的替代方案。我们并不太满意它按 topic/partition 计费的模型,这意味着我们多付了相当一部分费用。与此同时,AWS 每个月都会执行安全补丁,导致集群 rebalance 往往需要数小时才能完成。Ufff。
不过,真正促使我们最终愿意承担迁移成本的,是 AWS MSK 并不提供从 ZooKeeper 到 KRaft 的开箱即用迁移路径:
Amazon MSK supports in-place upgrades to most Apache Kafka versions. However, when upgrading from a ZooKeeper-based Kafka version to a KRaft-based version, you must create a new cluster. Then, copy your data to the new cluster, and switch clients to the new cluster. (source)
既然无论如何都被迫做一次集群迁移,为什么还要迁移到 AWS MSK 呢?
新的 KIP-1150 对我们很有吸引力,我们也希望至少在一个集群上先把 Diskless Kafka 用到生产环境中,也就是所谓的 CDC Warehouse。这个集群本质上只负责把源数据库 PostgreSQL 的数据搬到数据仓库 Snowflake(通过 Snowpipe connector)以及 OLAP 引擎 StarRocks(通过 Apache Flink connector)。这个链路对延迟并不是极致敏感;我们可以接受大约 200 ms 到 500 ms 的延迟来把数据送到目标端。这意味着我们有空间进行实验。
当时已经有一系列公司在提供某种形式的 Diskless Kafka 托管方案。值得一提的包括:
- WarpStream:商业方案,也是 2023 年最早引入 Diskless Kafka 概念并改变这个领域的先行者。
- Aiven Inkless:由 KIP-1150 创建者提出的替代方案,他们希望未来把 diskless 路线推进到开源 Kafka 中。我很期待那个未来!
- AutoMQ:一个较新的 Diskless Kafka 产品,当时已经在亚洲市场经受过生产规模测试。
最终,我们选择了开源的方案,因为这样我们可以推理它的行为,并理解它的实现。
于是,大约在冬天,我们开始制定从 AWS MSK 迁移到 AutoMQ 的计划。先剧透一下:它成功了,而且我们已经在生产环境运行 Diskless Kafka 数月了,从 2026 年 2 月底开始。

这是我们当前 CDC Warehouse 集群的规模。我们的 topic 保留 3 天数据,只有少数 topic 保留 7 天。因此图里的规模对应的是最近 3 天的数据。
部署 AutoMQ
在深入实际计划之前,先绕一步,解释一下我们在生产环境中实际是如何部署 AutoMQ 的。
我们选择了 BYOC(Bring Your Own Cloud)模式,按月订阅。订阅成本取决于所需 AKU(AutoMQ Kafka Unit)的数量;我们预留了 3 个 AKU,费用约为每月 400 美元。其余成本来自实际基础设施:AWS S3 bucket 与 API 调用、运行 AutoMQ 控制面的 AWS ECS 实例、监控等。
AutoMQ BYOC 控制台支持两种部署模式:K8S(以 EKS Pod 形式运行 Broker)和 IaaS(以 Auto Scaling Group 中的 EC2 实例运行 Broker)。我们决定使用 IaaS。
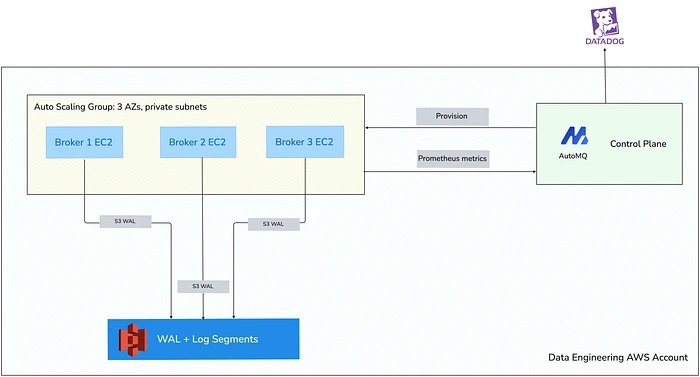
AutoMQ 部署方式的高层架构图。
再剧透一下:在我们的场景中,AutoMQ 运行两个多月后,总体成本大约比 MSK 低 50%,从每月 3,200 美元降到每月 1,600 美元,这已经包含 license 成本。最棒的是,如果我们突然需要承载更多流量,S3 成本并不会按比例上涨;我们可以批量写入更多 record,并把 S3 调用次数控制住。换句话说,我们的成本增长会更线性,而不是像之前 MSK 那样呈指数式增长。
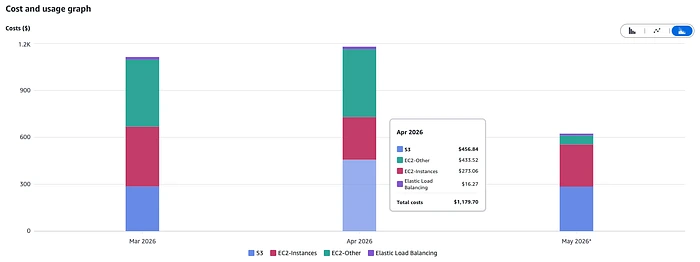
运行 AutoMQ 生产环境的基础设施成本。总体成本由这部分基础设施成本加上订阅费用构成。
迁移 topic 与 connector
现在回到迁移计划。如前所述,这个 CDC Warehouse 集群用于支撑我们的 CDC pipeline 以及一系列 Flink pipeline。
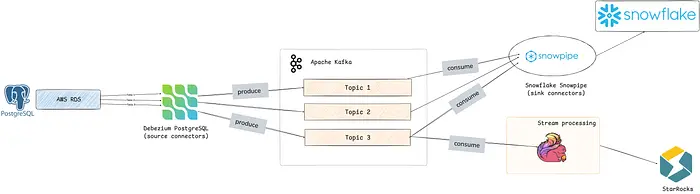
Kafka 中数据流动的高层概览:我们用 Debezium 捕获 PostgreSQL 源库中的 CDC 变更,然后用 Snowpipe 或 Flink 消费这些消息,并写入目标数据库。
幸运的是,AutoMQ 提供了自己的工具,用于在 Kafka 集群之间进行零停机迁移。他们称之为 AutoMQ Linking。它很好的地方在于会为 consumer 保留 offset:
The solution provides Offset-Preserving Replication, ensuring that all consumer offsets are maintained during the transition. This comprehensive approach allows for the smooth transition of consumers, Flink jobs, Spark jobs, and other infrastructure to the new clusters without disruption or data loss. (source)
流程相当简单:在集群 A(源集群)和集群 B(目标集群)之间设置 AutoMQ Linking。然后选择一些要迁移的 topic,并为它们开启 mirroring。你先把 producer 更新为使用新集群,然后再更新 consumer。如果一切正常,就在 AutoMQ 中 promote 这个 topic。最后,就可以从原始集群中删除旧 topic。就是这么简单。
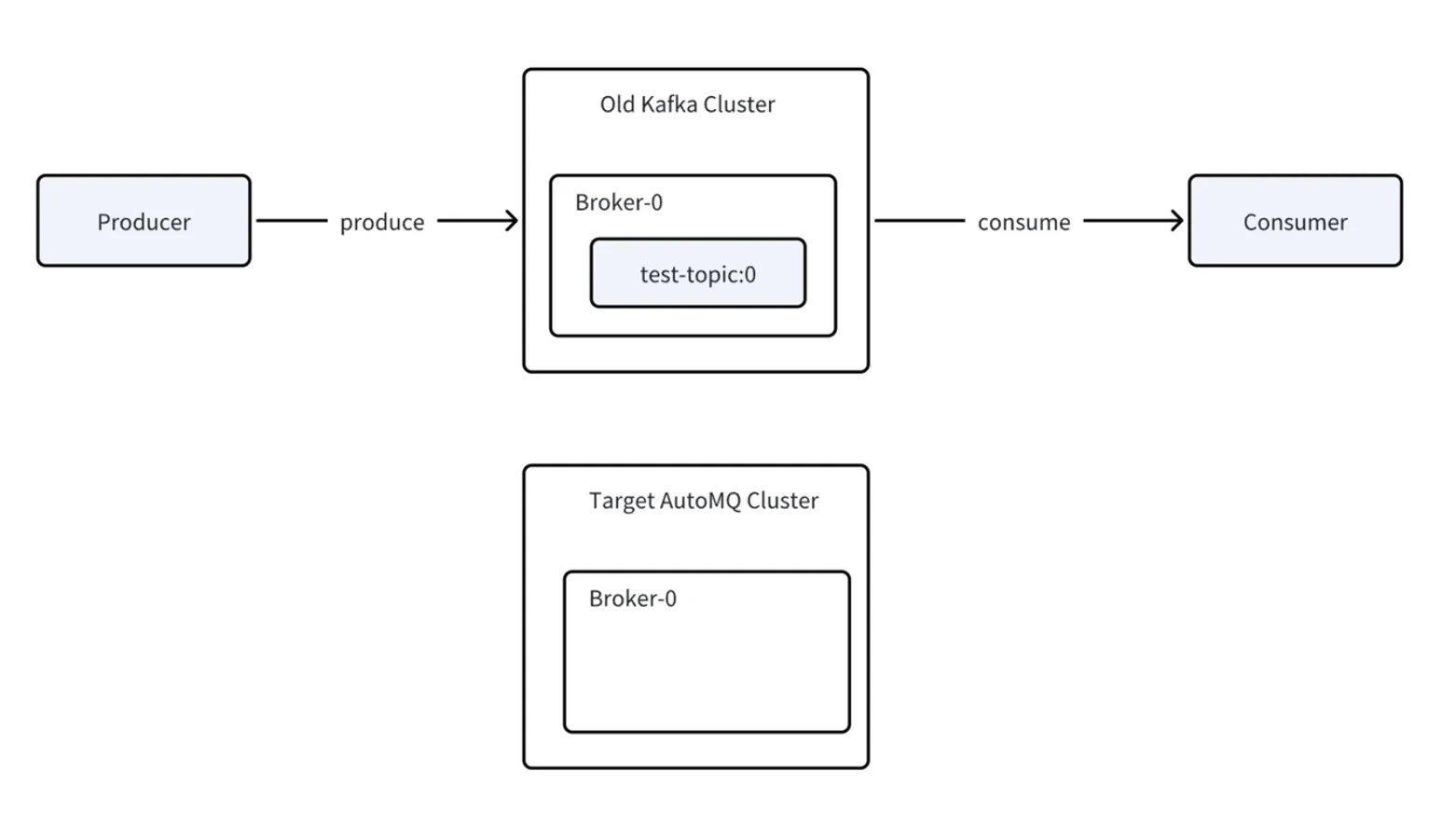
迁移到 AutoMQ 集群的简化流程图。
上图概括了迁移到 AutoMQ 集群所需的全部步骤:
- 目标集群已经搭建完成;选择要从源集群镜像数据和元数据到目标集群的 topic。
- 更新 producer,使其连接到新集群。在此期间,数据会被转发回原始集群;如果出现问题,用户可以直接回退。
- 接下来更新 consumer。它们不会立即开始处理数据;AutoMQ 会先检查源集群中的所有成员都已离线,并且 offset 已同步,然后再 promote consumer group。
- 一旦前置条件满足,consumer group 会被自动 promote。此时迁移完成,源 topic 可以安全删除。
我们再展开一点,并把 Kafka connector 也纳入考虑。归根结底,它们仍然是 producer(source connector)和 consumer(sink connector),但它们的 offset 状态并不在 consumer group 协议里,而是在 connect-offsets 内部 topic 中。这意味着你也需要镜像 Kafka Connect 的内部 topic。
需要记住的重要一点是:启用 AutoMQ Linking 后,集群之间的同步是双向的。当 producer 切换到新集群后,所有数据和元数据都会被转发回原始集群。这让回滚变得非常简单。同时,不需要停止 producer 或 consumer;迁移过程中任何时候都没有停机。
我们在几天内迁移了大约 150 个 Kafka Connector。
为了兼容 AutoMQ,我们对 connector 做的唯一配置变更,就是移除 tiered storage 设置。在我们的 CDC Warehouse 集群中,topic.creation.enable: true,因此我们需要设置合理的默认值,应用到每个新创建的 topic。
topic.creation.default.remote.storage.enable: "true"
topic.creation.default.local.retention.ms: "43200000" # 12 hours
topic.creation.default.retention.ms: "604800000" # 7 days
topic.creation.default.segment.ms: "14400000" # 4 hours
这是因为在 AutoMQ 中,Broker 禁用了 KIP-405 定义的 tiered storage 功能。这是合理的:数据已经在 S3 中了。如果不移除这些设置,你会看到:
Create Mirror Topic: avro.landing_pages_manager.public.treatment_type_tags
kafka-linking.create.progress.hide
org.apache.kafka.common.errors.InvalidConfigurationException:
Tiered Storage functionality is disabled in the broker.
Topic cannot be configured with remote log storage.
旁注:topic 自动创建
当 connector 被设置为自动创建 topic 时,connector 会创建一个 AdminClient,用来轮询集群元数据,检查指定 topic 是否存在;如果不存在,就用配置好的默认值创建它。
一开始 connector 工作得很好,但在 AutoMQ 集群一次升级后的重启之后,我们注意到大量 warning,例如:
[AdminClient clientId=connector-adminclient-dbz
Metadata update failed (org.apache.kafka.clients.admin.internals.AdminMetadataManager)
[kafka-admin-client-thread | connector-adminclient-dbz
org.apache.kafka.common.errors.TimeoutException: Timed out waiting for a node
assignment. Call: fetchMetadata
调查后发现,滚动重启后集群 IP 地址可能发生变化,但 AdminClient 内部可能仍然缓存着旧 IP。为了避免这个问题,需要确保 metadata recovery strategy 设置为 rebootstrap。幸运的是,这已经是 Kafka client 4.x 以上版本的默认值,但较旧 client 需要调整。这个 Kafka Connect 集群仍然是 3.8,因此我们在 connect 级别修改了配置:
admin.retries: 5
admin.metadata.recovery.strategy: rebootstrap
consumer.metadata.recovery.strategy: rebootstrap
producer.metadata.recovery.strategy: rebootstrap
Schema Registry 怎么办?
Schema 会持久化到一个专用 topic 中,默认是 _schemas,这个 topic 也需要迁移。流程与上面定义的完全一样。
在我们的场景中,我们分两阶段迁移:先迁移 topic 和 connector,并让 Schema Registry 服务继续指向旧 MSK 集群。只有在其他所有内容迁移完之后,我们才迁移最后一个仍然使用 MSK 的基础设施组件。
我们先搭建了一个新的 Kafka Schema Registry 服务,指向新的 AutoMQ 集群。然后为 _schemas topic 启用 AutoMQ Linking。但还记得我前面说过 AutoMQ Linking 建立后,数据会同步回原始集群吗?当我们部署这个服务时,用于存储 schema 的 topic 被自动创建了,因此在启用 mirroring 时它已经存在。AutoMQ 所做的事情,是把这个新的空 topic 与 MSK 集群中的 topic 同步。
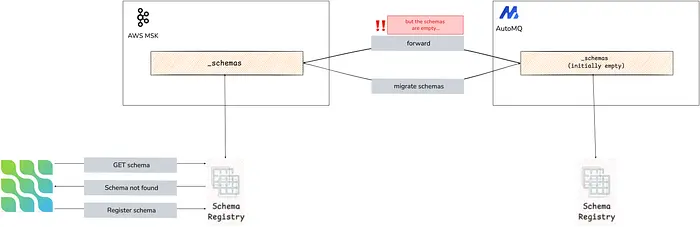
失误在所难免。
好吧,事后看来显而易见。最终 schema 被重新创建,并获得了新的 ID,我们不得不搭建一个 Schema Registry proxy,用来把旧 ID 翻译成新 ID。过程很痛苦,但它确实解决了问题,我们也学会了下次要更加注意操作顺序。
Flink pipeline 怎么办?
Flink job 归根结底也是 consumer,唯一不同在于这些 job 是有状态的,并通过 checkpoint 机制把 offset 存在 Flink state 中。幸运的是,AutoMQ 有一篇指南说明如何处理这类迁移。
在我们的场景中,我们选择重新分配 producer 和 consumer,并从 earliest offset 启动全新的 Flink job,即使这意味着要重新处理三天数据。我们不需要处理 savepoint,因为我们的 Flink SQL pipeline 并不太复杂,主要是从 Kafka 读取,做有限的数据转换,然后写回 Kafka 或 StarRocks。对于确实存在的一些常规 join,我们只是对必要的数据库表做了快照,以便重建 state。但话说回来,这是因为我们承受得起这种方式。一般来说,最好还是参考官方指南。
我们现在的状态
我们从 2 月底开始在生产环境运行 AutoMQ,并且对此感到满意。成本下降了,我们摆脱了 ZooKeeper,也不再需要为每月集群 rebalance 的影响做准备。后续我们会在另一篇文章中更深入地介绍性能、与 AWS MSK 的对比以及更多经验教训,敬请关注!
话虽如此,Fresha 团队并不打算止步于此。在改善公司内所有工程师 Kafka 使用体验的旅程中,我们还计划进行更多有趣的实验。我们也有兴趣迁移另一个仍然运行在 MSK 上的 Kafka 集群;它专门用于业务事件,因此低延迟变得至关重要。AutoMQ 支持这类 use case,可以使用 AWS FSx 等 WAL 存储选项来提供毫秒级延迟。我们还没有测试这里的极限,但完成后会继续分享。
最后,关于我们 roadmap 上计划的未来增强,还有 Topic Table feature:理论上它允许我们把数据直接分层到 Iceberg table 中。这对我们会非常有用,因为我们可以移除一些当前只是为了创建和维护 Iceberg table 而存在的 pipeline。
如果不是 Anton Borisov 坚持让我们试试 AutoMQ,上述一切都不可能发生。而 Paritosh Anand 则搭建了所有基础设施,并推动了与 AutoMQ 团队的沟通。我很感谢他们两位,帮助我们把最初的“迁离 MSK 需要什么?”变成了“我们现在已经在生产中运行 Diskless Kafka”。