前言
在之前的文章 原理剖析:一文搞懂 Kafka Producer(上) 中,我们介绍了介绍 Kafka Producer 的使用方法与实现原理。这篇将继续介绍 Kafka Producer 的实现细节与常见问题。
幂等性
在一个分布式的消息系统中,各个角色均有可能发生故障。以 Apache Kafka 为例,Broker 和 Client 都有可能会崩溃,Broker 与 Client 之间的网络请求与响应都有可能丢失。根据 Producer 处理这类故障时采取的策略,可以分为以下几种语义:
-
至少一次(At Least Once):当发生请求超时或者服务端错误时,Producer 重复尝试发送消息直至成功。这样做可以保证每条消息都被写入 Topic,但是可能会发生重复。
-
至多一次(At Most Once):在超时或报错时 Producer 不进行重试,每条消息仅发送一次。这样做可以避免消息重复,但也可能会导致消息丢失。
-
精确一次(Exactly Once):Producer 进行适当的重试,以确保每条消息会且仅会被写入 Topic 一次,既不重复,也不遗漏。Exactly Once 的语义是最理想的实现,它可以满足绝大多数业务场景的需求;但同时也是最难以实现的,它需要 Client 与 Broker 之间的密切配合。
Apache Kafka Producer 提供了两个级别的 Exactly Once 的语义实现:
-
幂等性(Idempotence):确保 Producer 在向某个 Partition 发送消息时,该消息会且仅会被持久化一次。
-
事务性(Transaction):当 Producer 同时向多个 Partition 发送消息时,确保这些消息要么都被持久化,要么都不被持久化。
这里我们主要介绍 Kafka Producer 幂等性的使用与实现,关于事务消息的实现原理可以参阅我们之前的文章 原理剖析| Kafka Exactly Once 语义实现原理:幂等性与事务消息 。
开启幂等性
Kafka Producer 开启幂等性是非常简单的,它只需要设置几个配置项,而无需修改任何其他代码(Producer 的接口并没有变化)。
相关配置项有:
acks:当指定数量的副本收到消息后,Producer 才会认为消息写入完成,默认为"all"。acks=all:Producer 会等待所有同步的(in sync)副本响应。acks=1:Producer 会等待 leader broker 响应。acks=0:Producer 不会等待任何 broker 响应,消息写入网络层后即认为写入成功。enable.idempotence:开启幂等性,保证每条消息写入且仅被写入一次,同时保证消息按照发送顺序写入,默认为"true"。
开启此配置时,需要保证 max.in.flight.requests.per.connection 不大于 5,retries 大于 0,acks 设置为 "all"
在使用时需要注意,幂等 Producer 仅能避免由 Producer 内部的重试策略(Producer、Broker 或网络出错)导致的消息重复,它无法处理以下几种情况:
- 幂等 Producer 仅保证 Session 级别的不重不漏。当 Producer 发生重启时,不能保证重启后与重启前发送的消息不重复。
- 幂等 Producer 仅保证 Partition 级别的不重不漏,不能保证向多个 Partition 发送的消息不重复。
- 当 Producer 出于各种原因发送超时时,即发送耗时超过
delivery.timeout.ms,Producer 会抛出TimeoutException。此时无法保证对应的消息是否已经被 Broker 持久化,需要由上层根据情况进行处理。
实现原理
为了实现幂等性,Kafka 引入了以下两个概念
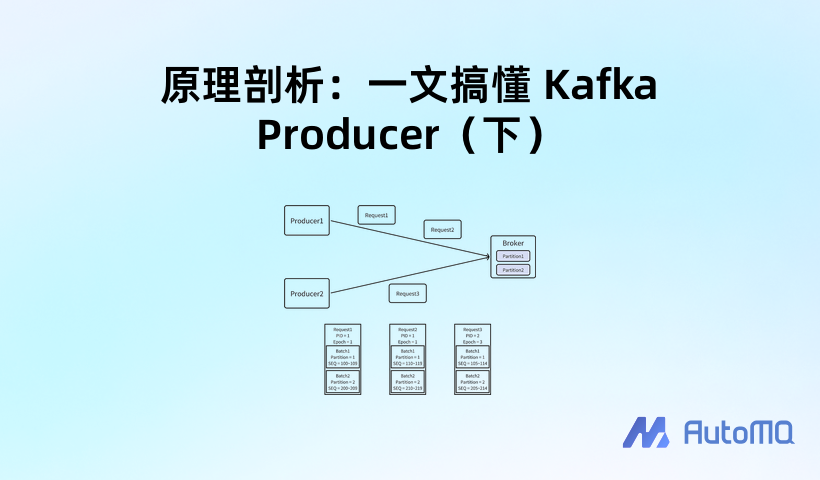
- Producer ID(以下简称 PID):Producer 的唯一标识。PID 由 Idempotent Producer 在首次发送消息前,请求 Broker 分配获得,是全局唯一的。PID 仅在 Producer 和 Broker 内部使用,不会暴露给 Client 使用者。
- Sequence Number(以下简称 SEQ):消息的序列号。该序列号在
(PID, Partition)维度上严格递增。事实上,SEQ 会存储在 Record Batch 的头中,作为 Batch 中第一条消息的 SEQ,Batch 中其它消息的 SEQ 依次递增。
值得一提的是,PID 与 SEQ 均会跟随消息持久化到 Log 中。
事实上,除了前述两个属性外,还有 Producer Epoch,它与 PID 结合才会唯一标识一个 Producer。它的在不同的场景下有不同的用途:
- 对于开启事务能力的 Producer(配置了
"transactional.id"),Producer Epoch 同样由 Broker 分配。这样做可以保证,多个具有相同 Transactional ID 的 Producer 中仅会有一个生效,即"Fence Producer"。 - 对于没有开启事务能力的 Producer,Producer Epoch 则由 Producer 自己维护。它会在需要重置序列号(Reset SEQ,后文会详细介绍)时增长,并将 SEQ 重置到 0。
下面分别介绍为了实现幂等性,服务端(Broker)与客户端(Producer)分别做了哪些操作。
服务端
Broker 会在内存中记录每个 Producer 的状态信息,包括 Producer Epoch 与每个 Partition 最新写入的 5 个 Record Batch 的元数据(包括 SEQ、offset、timestamp 等),用于判断 Producer 发送的请求是否存在重复或者遗漏。
此外,这些状态信息也会定期进行快照,Broker 在重启时会基于快照与 Log 中的信息恢复出这些状态信息。
值得一提的是,这里硬编码的 5 也是 Producer 配置 max.in.flight.requests.per.connection 的上限。具体原因在后文介绍。
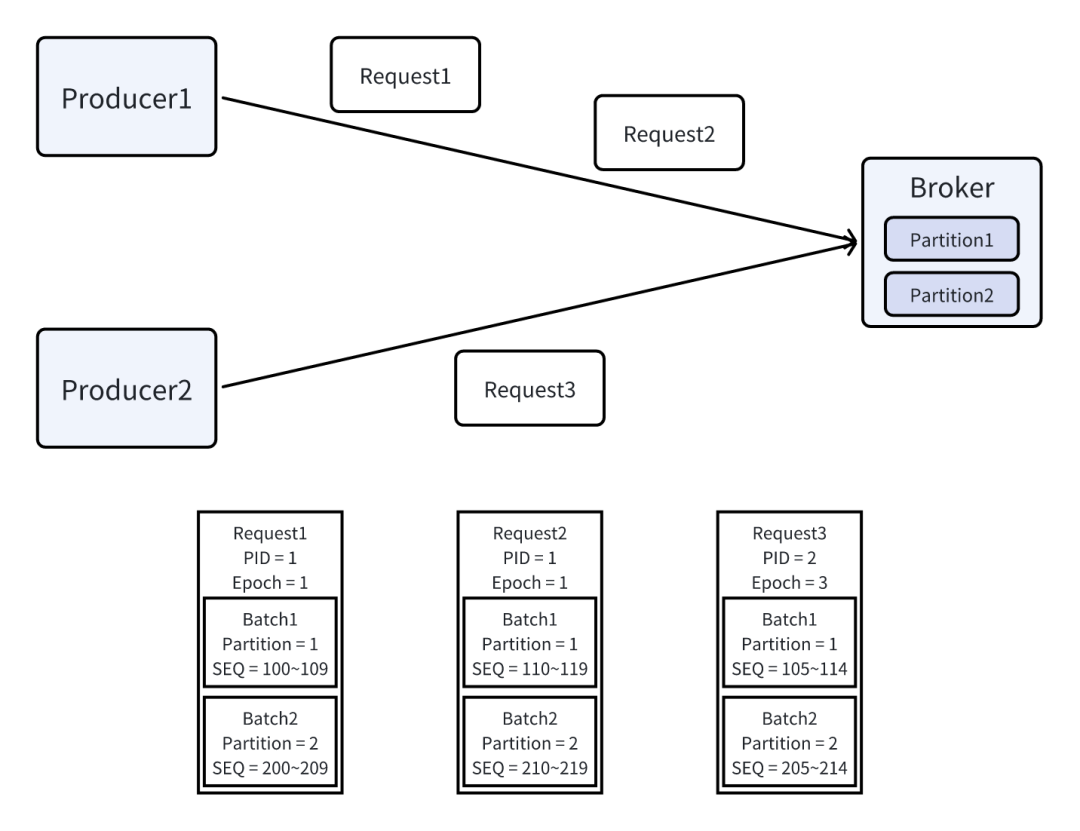
当 Broker 收到一个 Record Batch 后,在进行完必要前置操作后、真正持久化到 Log 前,会检查该 Batch 上的 PID、Producer Epoch 与 SEQ。具体地说:
- 检查该 Record Batch 是否与本地记录的 5 个 Record Batch 一致。若一致,则认为 Producer 出于某些原因重复发送了该 Record Batch,不进行任何操作,直接返回本地记录的元数据(主要为 offset)。
- 检查之前是否记录了该 PID 对应的状态信息。若没有,则检查 SEQ 是否为 0:若是,则认为这是一个全新的 Producer,记录该 Producer 相关信息并写入 Record Batch;若否,则报错
UnknownProducerIdException。 - 检查 Producer Epoch 是否与本地记录一致。若不一致,则检查 SEQ 是否为 0:若是,则认为该 Producer 出于某些原因重置了 SEQ,更新记录并写入 Record Batch;若否,则报错
OutOfOrderSequenceException。 - 检查 SEQ 是否与最近一次写入的 Record Batch 的 SEQ 连续。若连续,则缓存该 Record Batch 的元数据并写入;若不连续,则报错
OutOfOrderSequenceException。
经过上述处理,可以确保在客户端侧,由同一个 Producer 向同一个 Partition 写入的 Record Batch 都是连续的(基于 SEQ),不会存在遗漏或重复。
客户端
Producer 对于幂等性的处理则相对更加复杂,主要有以下两个难点:
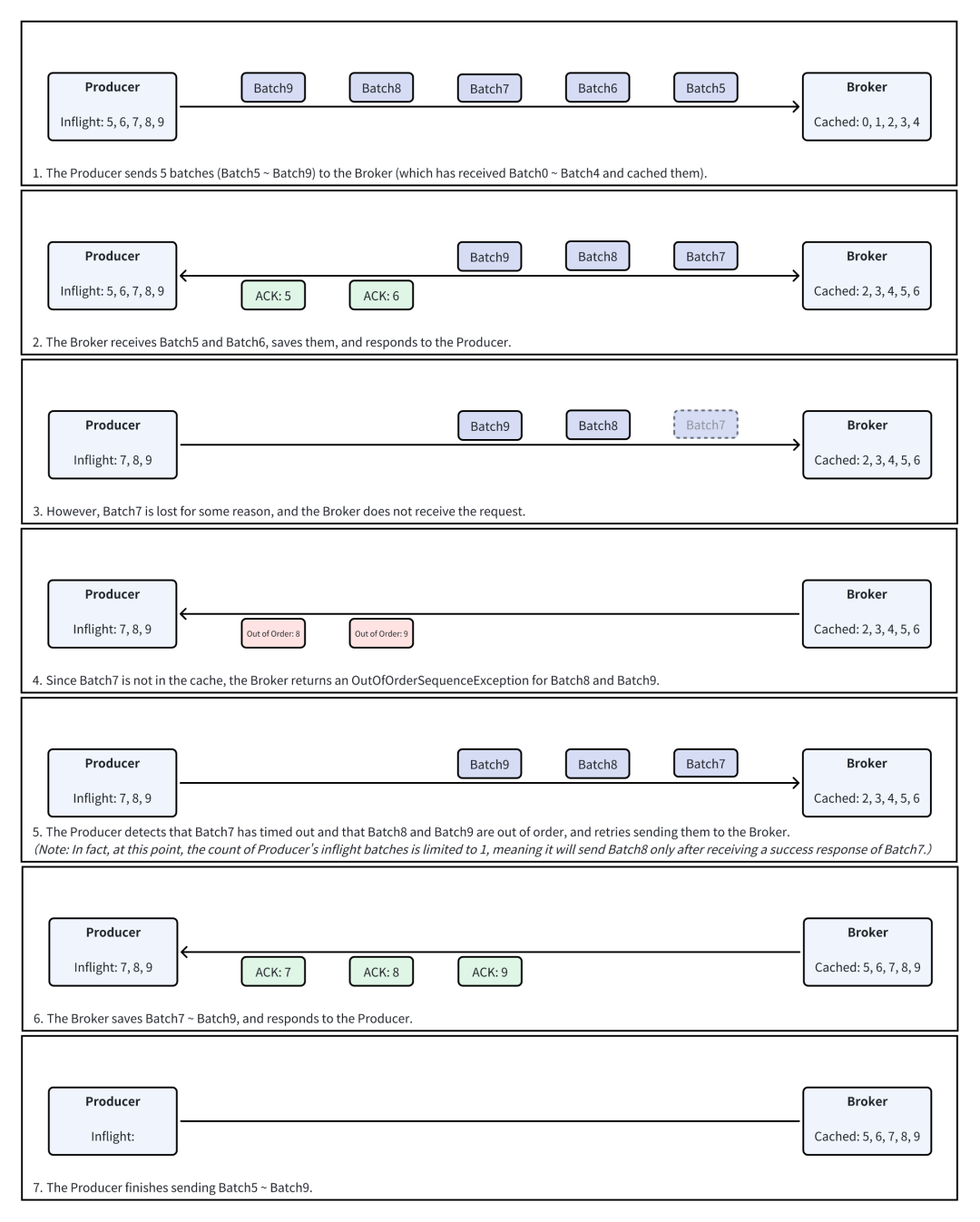
- Producer 在发送时可能会发生超时。在超时时,可能存在两种情况:“Broker 没有收到请求”或“Broker 处理了请求,但 Producer 没有收到响应”。这会导致 Producer 难以确认某个 Produce 请求超时时,Broker 是否已经完成持久化。
- Producer 可能会向同一个 Broker 同时发送多个 Produce 请求。当其中一个或多个报错时,需要根据不同情况,对它们以及后续请求采取不同处理方式。
基本概念
在介绍 Producer 发送流程前,先介绍几个基本概念
在途 Batch(Inflight Batch):Producer 会按 Partition 维度,记录已经发送请求但尚未收到响应的 Batch。特别地,对于幂等 Producer,还会额外记录每个 Inflight Batch 的 SEQ,并按照 SEQ 排序。
未解决的 Batch(Unresolved Batch):之前提到,Producer 在发送消息时会进行数次重试,直至总耗时超出 delivery.timeout.ms。如果某个 Batch 发生了 Delivery Timeout,则认为其为 Unresolved。
当某个 Batch 被标记为 Unresolved 时,Producer 无法判断 Broker 是否已经持久化这个 Batch,则只能通过检查这个 Batch 的后续 Batch 是否被 Broker 持久化(亦或报错 OutOfOrderSequenceException):若后续 Batch 写入成功,则认为它之前的 Unresolved Batch 也已经写入完成;否则,则认为前面的 Unresolved Batch 没有写入完成,需要重置 SEQ。
提升 Epoch(Bump Epoch)与重置 SEQ(Reset Sequence Number):当 Producer 遇到无法通过重试解决的问题时(例如,Inflight Batch 均响应完成,但仍存在 Unresolved Batch 时;Broker 报错 UnknownProducerIdException 时),会执行 Bump Epoch & Reset SEQ 的操作。
具体地说,会将 Producer Epoch 加一,并将出错 Partition 的所有 Inflight Batch 从零开始重新编号重新发送,并清空 Unresolved Batch。
发送流程
幂等 Producer 发送一个 Batch 的流程如下:
在发送 Batch 的过程中,Producer 还会驱动处理一些其他事件(例如处理超时 Batch),这些步骤会用括号标出。
- 判断 Unresolved Batches 的状态:如果确认 Unresolved Batch 实际已写入完成,则将其从 Unresolved Batches 中移除;如果确认它实际没有写入(判断条件:Inflight Batches 为空),则 Bump Epoch & Reset SEQ。
- 检查目前该 Partition 能否发送新的 Batch。不能发送的场景包括:存在 Unresolved Batch;之前发生了 Bump Epoch 且仍存在老 Epoch 的 Inflight Batch;之前某个 Batch 正在重试(也就是说,幂等 Producer 在重试时,Inflight 始终为 1)。
- 如果之前发生了 Bump Epoch,且已经不存在老 Epoch 的 Inflight Batch,则 Reset SEQ。
- 获取对应 Partition 的下一个 SEQ,并设置到 Batch 中。
- 将 Batch 加入到 Inflight Batches 中。
- 检查是否存在 Delivery Timeout 的 Batch。若存在,则将其加入到 Unresolved Batches 中。
- 向 Broker 发送 Produce 请求,等待响应。
- 收到响应后,检查 Error Code:若为不可重试错误(例如
AuthorizationException),则 Bump Epoch & Reset SEQ,并向上层报错;若为可重试错误(例如TimeoutException),则加入重试队列,等待下次发送。 - 如果可重试错误是
UnknownProducerIdException,且之前没有 Reset SEQ,则 Bump Epoch & Reset SEQ 并重试;否则直接重试。 - 如果可重试错误是
OutOfOrderSequenceException,且“Unresolved Batch 为空”或“该 Batch 恰好为 SEQ 最大的 Unresolved Batch 的下一个”,则 Bump Epoch & Reset SEQ 并重试;否则直接重试。 - 从 Inflight Batches 中移除,并向上层返回成功。
Inflight Request 上限
前文中提到,Producer 的配置 max.in.flight.requests.per.connection 存在上限 5,这同时也是 Broker 缓存每个 PID 在每个 Partition 发送过的最新的 Batch 的数量。这样做的原因是,当 Inflight Request 数量(例如 2)超过 Broker 缓存的 Batch 数量(例如 1)时,存在以下反例:
- Producer 向 Broker 先后发送了两个 Produce Request,且这两个请求中均包含一个发送给 Partition p1 的 Batch,记为 b1 与 b2,其中 b1 SEQ < b2 SEQ。
- Broker 将 b1 与 b2 依次持久化完成(此时,Broker 缓存中会记录 b2 的元数据),但由于网络问题,Producer 没有收到响应。
- Producer 发现超时后重试,重新发送包含 b1 的 Produce Request。
- Broker 收到 Request 后发现 b1 SEQ 小于缓存中的 b2 的 SEQ,可以推测出该消息为重复的,不应写入,而是直接返回 offset 等信息;但由于缓存中并没有 b1 相关元数据,Broker 也就无法返回 offset 信息。
以上就是 Inflight Request 数量不能超过 5 的原因。
其他细节
Producer Epoch 溢出的处理
当 Producer Epoch 溢出时(类型为 short,最大值为 32767),Producer 会将 PID 与 Epoch 重置,并向 Broker 请求分配一个新的 PID 与 Epoch,并 Reset SEQ。
SEQ 溢出的处理
当 SEQ 溢出时(类型为 int,最大值为 2147483647),下一条消息的 SEQ 会轮转回 0。考虑到 Inflight Batch 的数量与 Batch 中消息的数量的限制,不会发生问题。
UnknownProducerIdException 的处理
UnknownProducerIdException 报错常发生于以下场景:由于 Log Retention 限制,Broker 将 Log 中某个 Producer 发送的消息均删除了,此时 Broker 重启后缓存中不再有该 Producer 的状态信息。如果此时 Producer 尝试接着之前的 SEQ 发送消息,由于 Broker 无法识别 PID,则会报错。
为了处理这种情况,Producer 只需 Bump Epoch 并 Reset SEQ,重新发送消息即可。
示例
Broker 没有收到 Produce 请求
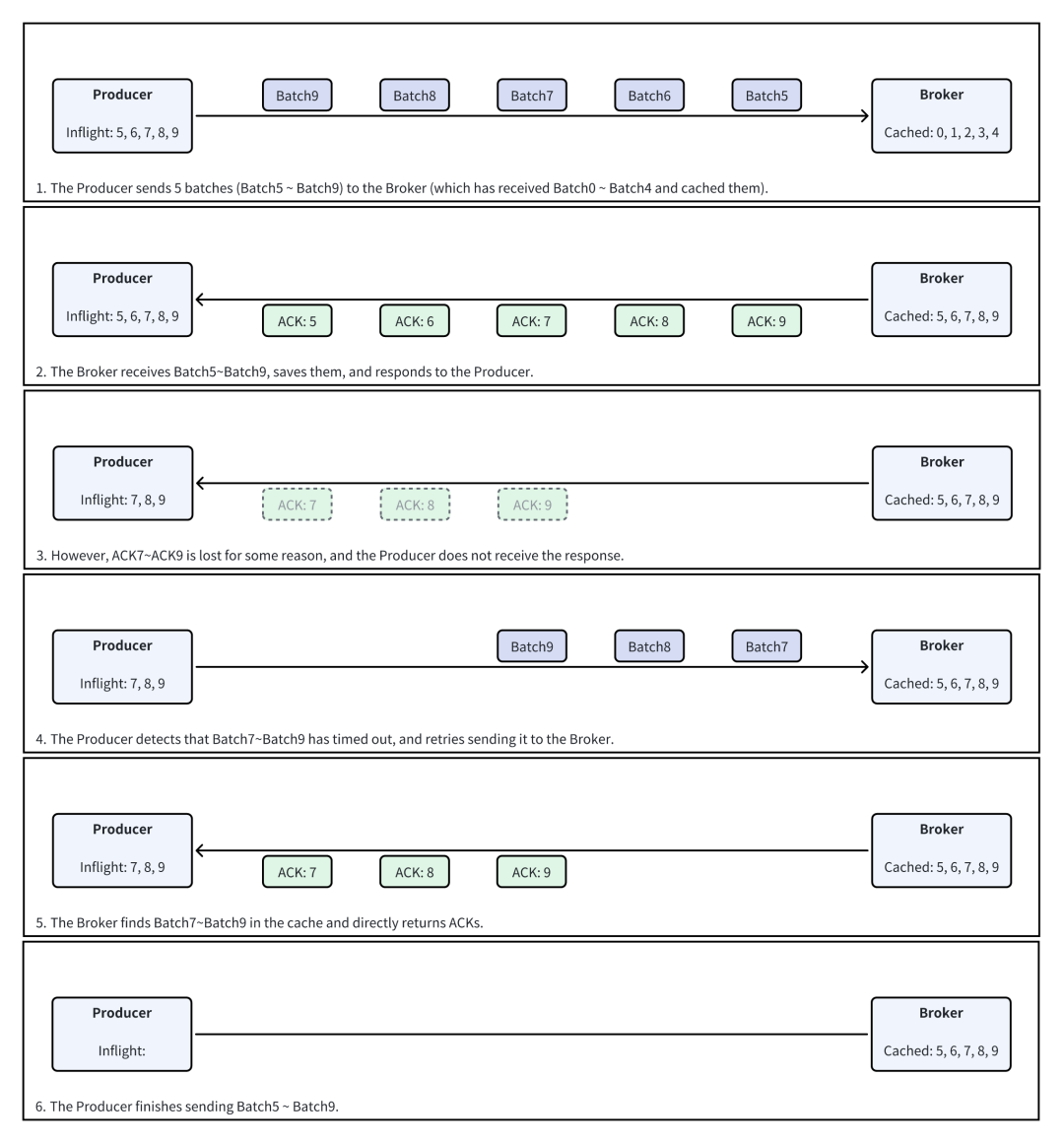
Producer 没有收到 Produce 响应
实现细节
下面介绍一些前文未涉及的 Kafka Producer 的实现细节。
消息压缩
Kafka Producer 支持在客户端对消息进行压缩,以减少消息的网络传输成本与存储成本。可以通过 Producer 配置 compression.type 来指定压缩时使用的算法,支持的选项有 none、gzip、snappy、lz4、zstd,默认为 none,即不进行压缩。
开启压缩后,可以节约网络带宽与 Broker 存储空间,但是会增加 Producer 与 Broker 的 CPU 消耗。此外,由于压缩是以 Batch 维度进行的,更好的攒批(更大的 Batch)会带来更好的压缩效果。
在实现消息压缩时,会存在这样一个矛盾:只要在真正将消息压缩到 Batch 中之后,才能判断它实际(压缩后)占用了多大的大小;但为了不超过 batch.size 的限制,需要在消息写入 Batch 之前就判断其压缩后的大小。
为了解决这个问题,Kafka 提出了一个自适应的压缩率估计算法。其逻辑如下:
- 维护一个 Map,其中记录了每个 Topic 上各个压缩算法的“估计压缩率”,初始值为 1.0。
- 当某个 Batch 写满并压缩完成后,计算其“实际压缩率”(压缩后大小 / 压缩后大小)。
- 基于这个实际压缩率调整估计压缩率。
- 如果实际压缩率 < 估计压缩率,将估计压缩率向实际压缩率靠近,最大减少 0.005。
- 如果实际压缩率 > 估计压缩率,将估计压缩率向实际压缩率靠近,最大增加 0.05。
- 在尝试向新的 Batch 写入消息时,将使用新的估计压缩率 * 1.05 作为估算值。
除此之外,为了应对极端情况(消息可压缩性波动导致估计值大幅偏离实际值),Kafka 还支持了 Batch 分裂的逻辑。
Batch 分裂
Batch 分裂(Split Batch)是 Kafka Producer 为了应对如下场景实现的功能:当上文中提到的压缩率估计值大幅低于实际值时,可能会导致在一个 Batch 中写入了过多的消息以至于超出了 Broker 或 Topic 的限制(message.max.bytes 或 max.message.bytes),Broker 会拒绝写入并报错 MESSAGE_TOO_LARGE。
当发生这样的问题时,就需要 Producer 将过大的 Batch 拆分开并重新发送,具体流程如下:
- Producer 收到
MESSAGE_TOO_LARGE报错。 - 重置前文中提到的“估计压缩率”至
max(1.0, 该过大 Batch 的实际压缩率)。 - 将该 Batch 解压,并将解压出的消息基于
batch.size重新攒批。由于重置了估计压缩率,这会产生多个 Batch,并重新加入发送队列。 - 如果开启了幂等性或事务性,为新的多个 Batch 设置 SEQ。
- 释放老的 Batch 所使用的内存。
监控指标
Kafka Producer 暴露了一些监控指标,可以通过 Producer 配置 metrics.recording.level 来指定 metrics 级别,支持的选项有 INFO、DEBUG、TRACE,默认为 INFO。目前 Kafka Producer 中各监控指标级别均为 INFO,即无论配置如何均会采集。
下面是 Producer 暴露的 metrics 及其含义。
batch-size-avg、batch-size-max:每个 Batch 的大小。如果开启了消息压缩,则为压缩后大小。batch-split-rate、batch-split-total:Batch 分裂的频率与次数。bufferpool-wait-time-ns-total:从 Buffer Pool 中等待分配内存的耗时。buffer-exhausted-rate、buffer-exhausted-total:从 Buffer Pool 中分配内存超时的频率与次数。compression-rate-avg:Batch 的平均压缩率。node-{node}.latency:指定 Node 响应 Produce 请求的延时(从发送请求到收到响应),包括成功与失败的所有请求。record-error-rate、record-error-total:发送消息(而非 Batch)失败的频率与数量,包括同步调用阶段失败与异步调用阶段失败。record-queue-time-avg、record-queue-time-max:Batch 从创建到发送等待的耗时。record-retry-rate、record-retry-total:重试发送消息的频率和数量,不包含 Split Batch 导致的重试。record-send-rate、record-send-total:发送消息的频率和数量。record-size-avg、record-size-max:每个 Batch 中最大的消息(压缩前)的平均大小与最大大小。注意,record-size-avg并不是消息的平均大小。records-per-request-avg:每个 Produce 请求中消息的数量。request-latency-avg、request-latency-max:Broker 响应 Produce 请求的延时(从发送请求到收到响应),包括成功与失败的所有请求。topic.{topic}:Topic 粒度的各 metrics,包括.records-per-batch、.bytes、.compression-rate、.record-retries、.record-errors。{operation}-time-ns-total:Client 中各接口的总执行耗时,包括flush、metadata-wait、txn-init、txn-begin、txn-send-offsets、txn-commit、txn-abort。
常见问题
下面是一些在使用 Kafka Producer 时常遇到的问题与原因。
发送超时
Producer 发送超时的可能原因有很多,例如网络问题、Broker 负载过高,下面介绍两种由 Producer 导致的发送超时的情况。
-
Callback 耗时过长:Producer 支持在发送消息时注册回调,但该回调会在 Producer 的 sender 线程中执行。如果用户编写的回调方法执行了一些“重操作”,阻塞了 sender 线程,会导致该 Producer 的其它消息无法被及时发送,进而超时。
-
Callback 死锁:在 Callback 中同步调用 send 方法会导致死锁。举例如下,在 Callback 方法中检查是否发生错误,如果发生错误则调用
producer.send().get();正如前文所述,Callback 会在 sender 线程中执行,这样做会导致“阻塞 sender 线程的同时,等待 sender 线程执行”,发生死锁。
发送线程被阻塞
尽管 Kafka Producer 在发送消息时是异步的,但仍有一小部分操作是同步执行的。当这些同步操作出于某些原因被阻塞时,会导致调用 KafkaProducer#send 方法的线程也被阻塞。常见的发生阻塞的原因有:
-
刷新 Metadata 超时:在某些情况下,Producer 在发送消息前需要请求 Broker 刷新 Topic 元数据,该操作会在 send 的同步阶段执行。如果 Broker 出于某些原因无法提供服务或响应超时,会导致 Producer 被阻塞直至超时。
-
Producer Buffer 满:当 Producer 发送消息的速率过快,以至于超过 Broker 的处理能力或被 Broker 限流时,未被发送的消息会积攒在内存(Buffer Pool)中。当 Producer Buffer 被耗尽时,send 方法将被阻塞,直至出现可用 Buffer 或超时。
CPU/内存占用高
会有很多原因导致 Kafka Producer 的 CPU 与内存占用升高,下面介绍一些由 Kafka Producer 内部导致的 CPU 或内存占用升高的可能情况,实际排查时还应通过采集火焰图等手段准确定位问题。
CPU 占用高
-
Producer 攒批的大小越小,发送 Batch 的频率越高,CPU 占用越高。
-
开启消息压缩会导致 Producer CPU 占用升高。
-
Producer 会缓存历史一段时间使用过的 Partition 信息及其 Leader Node,并在发送消息遍历所有 Node 并检查是否存在待发送的 Batch。所以 Producer 涉及的 Partition 分散的 Node 越多,其 CPU 占用越高。
内存占用高
-
Producer 发送消息的速率超出了 Broker 的承载能力,导致消息堆积在 Buffer Pool 中,这会导致内存占用升高。
-
Producer 攒批的大小越大,(由于每次创建 Batch 会分配一整块内存)内存“浪费”越多,内存占用越高。
-
开启消息压缩时,执行压缩操作需要额外的缓冲区,这会导致内存占用升高。
Fatal Error 后无法发送
当 Kafka Producer 开启了事务时(配置了 transactional.id),如果在执行事务操作时发生了 Fatal Error,例如 ProducerFencedException,会导致该 Producer 的后续所有消息均发送失败(无论是否使用了事务),只能重启 Producer 解决问题。