
关于千寻位置
千寻位置是一家时空智能基础设施公司,成立于 2015 年 8 月。公司基于北斗卫星系统(兼容 GPS、GLONASS、Galileo)基础定位数据,利用遍布全球的 5000 多座 GNSS 星基/地基增强站、自主研发的定位算法及大规模互联网服务平台,为用户提供厘米级定位、毫米级感知、纳秒级授时的时空智能服务。2019 年 10 月,公司完成 10 亿元 A 轮融资,估值超过 130 亿元。
业务背景
千寻位置自 2015 年成立开始就利用北斗卫星系统以及自身的定位算法在水利、矿山、智慧城市、智慧交通等多个领域提供行业解决方案,赋能各行各业。企业内部来自定位基站、硬件终端设备的大量数据以及对应的监控、Trace 和日志等信息都需要经过 Apache Kafka 分发给下游消费用于进一步的分析与处理。随着业务高速发展,日均处理数据已达 百亿 。
千寻位置原先使用的是 Kafka,但是随着硬件终端的增长和业务的快速发展,对应的数据流量也快速增长,Kafka 带来的的问题日益严峻。AutoMQ 得益于其将持久性卸载至对象存储、块存储的共享存储架构,相比 Kafka 不仅可以明显降低我们的成本,同时还具备极速弹性、便于运维的特点,成为我们优化成本改进架构的不二选择。凭借 AutoMQ 对 Apache Kafka 100% 的完全兼容,使得千寻位置无需调整原有架构以及 Apache Kafka 周边的其他所有设施,即可无缝迁移至 AutoMQ,解决过去 Apache Kafka 的一系列痛点。下图是应用 AutoMQ 后千寻位置数据平台的架构图:
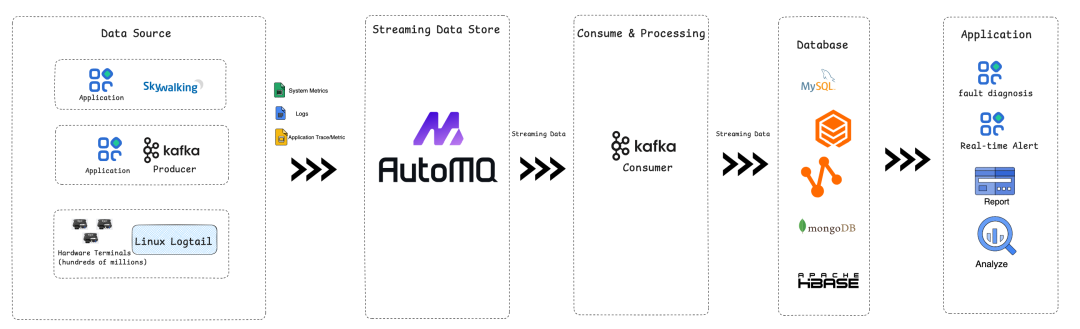
千寻位置写入AutoMQ的数据主要分为以下几类
系统监控数据 :通过一个类似 falcon_agent 的一个组件直接将机器监控数据发送给 AutoMQ 。主要是虚拟机的系统监控数据,例如磁盘、CPU、网络等。利用这些数据千寻位置下游的监控和报警系统可以及时识别虚拟机的一些异常。
用户数据 :用户数据主要通过 Kafka Producer 或者 Logtail 的方式发送给 AutoMQ。其中来自于 Logtail 的数据是来自于千寻位置 上亿个终端 的数据。他们来自行业无人机、测绘设备、车载定位终端等。写入吞吐为 600 MB/s ,每天写入消息达 百亿条以上 。此外用户数据,还包含 两条关键链路 ,写入吞吐为 150 MB/s ,并且必须保证低延迟不丢数据,否则会影响一些关键报表的准确性。用户数据最终落库后都会由其他应用程序进行分析并且产生诸如用户行为分析、用户日活趋势、重点客户分析、基站数据分析等重要报表来辅助企业决策,优化千寻位置各产品的服务水平。
应用 Trace/Metric 数据 : 应用程序的 trace 和 metric 信息则通过 skywalking agent 发送给 AutoMQ,用于对应用的实时监控、报警和问题诊断。
为什么选择使用 AutoMQ
对于千寻科技来说,最主要的诉求还是希望尽快降低成本,以及解决 Kafka 的弹性问题。Kafka 的痛点主要体现在如下的几个方面:
存储成本高昂 :Kafka基于 Apache Kafka 的 ISR 多副本机制来保证数据持久性,算上三副本和 SSD 云盘的价格,单位存储的价格高达 3.x 元/月/GB 。在云上,EBS 本身已经有多副本的高持久性保证,而 Apache Kafka 本身基于 ISR 多副本来保证数据持久性则会造成额外的存储空间浪费。此外,EBS 作为高性能、高持久性的块存储拥有较为高昂的单位存储成本。
存算不分离导致额外成本开销 :Kafka 本质还是存算一体的架构。为了支持更大的写入吞吐需要升配时,计算和存储都需要同时升配,这对千寻位置的应用场景来说非常不友好。千寻位置的所有数据都会先统一落库到不同类型的数据库中,在 Kafka 中的保留时间 仅为2小时 。Kafka 当容量不足以支撑写入流量需要扩容时需要对计算和存储层同时进行扩容,导致大量的存储空间浪费,而客户仍然需要为这些限制的资源付费,导致成本随着写入流量的增长而大幅度增长。
缺乏弹性 : Kafka 存算一体化的架构使得其在扩缩容时必须要进行分区数据的复制,不仅会占用大量磁盘、网络 IO,同时其执行过程也耗时较长,不能很快地完成集群的扩缩容。千寻位置 Kafka 集群随着业务的增长必然需要面临集群容量不足需要扩容来承载更大流量的情形。Kafka 扩容时由于需要将分区数据迁移到新的节点上,这个过程需要消耗较长的时间,并且必须人工介入,有较高的运维成本。
在充分调研 AutoMQ 以后,我们发现其创新的存储架构可以显著帮助我们降低Kafka 云账单的成本并且具备极强的弹性能力,很好的解决了千寻位置当前的痛点:
计算、存储成本可以显著降低 :AutoMQ 将所有数据存储到对象存储,对象存储的价格为 0.12元/月/GB ,相比 Kafka 基于 SSD 多副本的单位存储价格具备 数量级的成本优势 。此外,AutoMQ 通过创新的共享存储架构,计算层的 Broker 是无状态的。结合 AutoMQ 内置的持续流量重平衡能力,我们可以在很短的时间内对计算层单独进行安全、自动化和快速地扩缩容行为。这意味着在业务低峰时期或者某些流量减少的集群中,我们可以缩小集群规模节约成本。
计算和存储彻底分离更加经济 :与 Kafka 不同的是,AutoMQ 的计算层和存储层完全解耦。存储层完全是按需使用的。计算层可以单独根据所需要承载的流量进行快速、安全地扩容和缩容。这种灵活的架构最终也会反应到成本的降低。千寻位置的流量模型主要是写入流量较大,但是存储保留时间短。因此,AutoMQ 可以单独对计算层进行扩容而不引起存储成本的上升,相比 Kafka 可以帮助我们节约很多的成本。
极速弹性解放运维 :千寻位置数据基础设施的成本不仅仅来自于云资源和服务的消耗,同时也包含人力成本。相比 Kafka,AutoMQ 彻底解决了 Kafka 本身的弹性问题。AutoMQ 将数据持久性卸载至云存储,扩缩容期间无需进行分区数据的复制,只需修改元数据,在秒级即可完成分区的迁移。另外其内置的自动重平衡组件可以帮助集群在扩速容时自动做到流量均衡避免数据倾斜的问题。过去 Kafka 集群需要扩容时,扩缩容操作需要数十分钟,并且扩容后需要手工引流分区才能完成流量的迁移。为了保障扩容顺利完成,我们需要提前做好预案,整个团队一起在晚上等待业务低峰期值班完成扩容,并且等待集群流量均衡。使用 AutoMQ 以后,集群扩容成为了一个低风险、自动化、常态化的运维操作,大大降低了我们处理 Kafka 集群扩缩容时的人力成本,并且整个扩容过程变得更加安全、快速与可靠。
此外,AutoMQ 可以和 Apache Kafka 100%完全兼容 也是我们选择的重要原因。千寻位置本身围绕 Apache Kafka 的体系已经建设了大量的应用程序和数据基础设施。得益于 AutoMQ 对 Apache Kafka 的完全兼容,我们整体数据平台的架构以及上下游各种各样的数据基础设施都无需做任何改造,可以无缝迁移,大大降低了迁移难度和消除了潜在的迁移风险。
AutoMQ 在千寻位置的落地和实施
由于 AutoMQ 和 Apache Kafka 完全兼容,整个迁移过程也十分顺利。例如 skywalking 和 logtail 等组件经过测试均可以完全兼容 AutoMQ,无需做任何改造。在 PoC 完成后,我们采用如下基于切流的方式顺利完成了从 Kafka 替换为 AutoMQ。
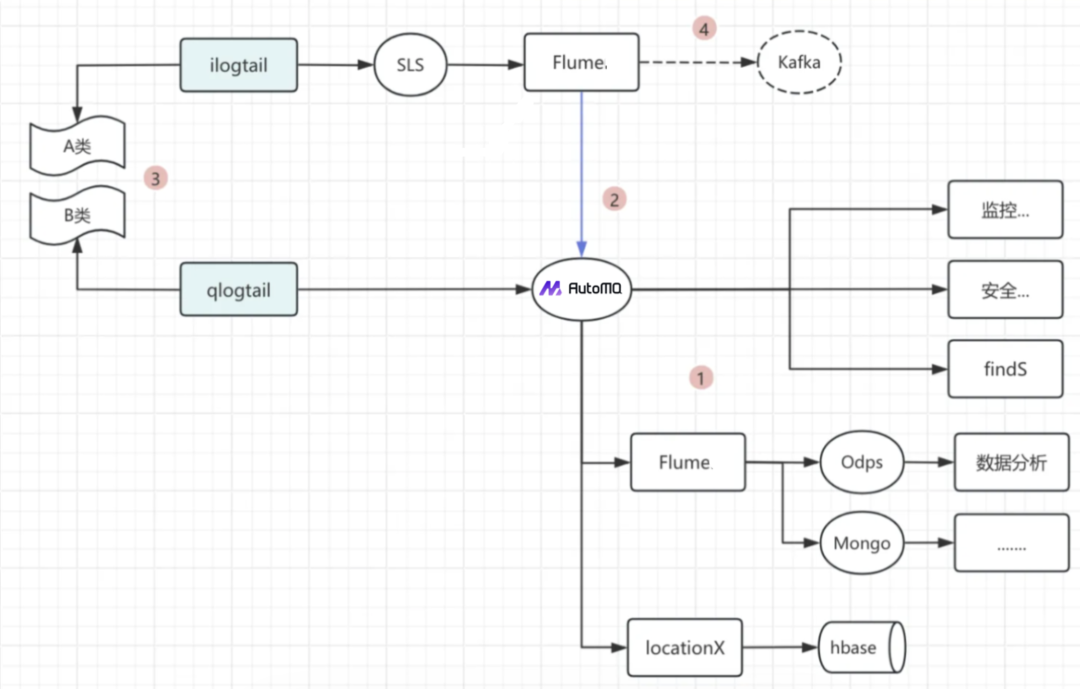
Flume 实现双写,同时写老的 Kafka 和新的 AutoMQ
所有消费、投递的系统切换到新的 AutoMQ
在服务器上灰度用新的 logtail 客户端取代老的客户端,新的客户端指向 AutoMQ
灰度切换完,下线老的 Flume 和 Kafka
收益和展望
总体而言,AutoMQ 是一款极具成本、性能和弹性优势的新一代 Kafka。上线 AutoMQ 以后,预计 成本降低 50% 以上 。
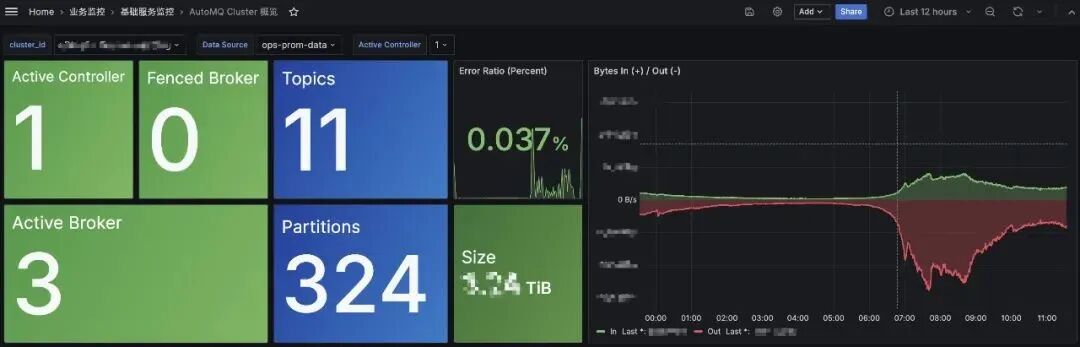
某个集群数据脱敏展示